들어가기 전에
Excel의 Correl 함수는 방대한 데이터에서 노이즈를 걸러내는 데 도움이 될 수 있습니다. 상관 계수를 계산하는 것은 숨겨진 추세를 찾고 더 현명한 결정을 내리는 데 필요한 비밀 무기입니다. Excel에서 Correl 함수를 사용하는 방법을 소개합니다.
권현욱(엑셀러) | 아이엑셀러 닷컴 대표 · Microsoft MVP · 엑셀 솔루션 프로바이더 · 작가

이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: Uncover Hidden Data Trends With Excel's CORREL Function
- URL: https://www.makeuseof.com/excel-data-trends-correl-function/




Excel의 CORREL 함수란 무엇인가요?
Correl은 두 데이터 집합 간의 관계를 측정하는 Excel의 통계 함수입니다. 이 함수는 두 변수가 선형적으로 얼마나 강하게 연관되어 있는지를 나타내는 -1에서 1 사이의 값인 상관 계수(coeffient)를 계산합니다. 다음은 Excel에서 Correl 함수의 구문입니다.
=CORREL(array1, array2)
array1과 array2는 분석하려는 두 데이터 범위입니다.
상관 계수 1은 완벽한 양의 상관 관계를 의미하며, -1은 완벽한 음의 상관 관계를 나타냅니다. 값이 0이면 선형 관계가 없음을 의미합니다. 이러한 방식으로 Correl은 데이터에서 이러한 관계의 강도와 방향을 정량화하는 데 도움이 됩니다.
CORREL 함수를 위한 데이터 준비하기
Correl 함수를 사용하기 전에 데이터를 올바르게 준비하는 것이 중요합니다. 먼저 분석하려는 각 변수에 대해 데이터를 두 개의 개별 열 또는 행으로 구성하는 것으로 시작해야 합니다.
각 데이터 요소에 다른 데이터 집합에 해당하는 값이 있는지 확인합니다. 누락된 값이 있는 경우 Excel은 상관 계수를 계산할 때 해당 데이터 요소 쌍을 무시합니다.
데이터에 이상값이나 불일치가 있는지 확인하는 것도 중요합니다. 이러한 요소는 상관 계수에 상당한 영향을 미치고 결과를 왜곡할 수 있습니다. 약간의 데이터 정리는 Excel 분석에서 큰 도움이 되므로 이러한 값이 전체 추세를 대표하지 않는 경우 제거하거나 조정하는 것이 좋습니다.
Excel에서 CORREL 함수를 사용하는 방법
이제 Correl 함수의 기능과 데이터 준비 방법을 이해했으니, 예제를 통해 Correl 함수가 어떻게 작동하는지 살펴보겠습니다. 지난 해의 데이터를 분석하는 영업 관리자가 있다고 가정합니다. 월별 판매 수익, TV 광고 지출, 라디오 광고 지출이라는 세 가지 데이터 집합이 있고 각각 200개의 데이터 포인트가 있습니다.
판매 수익과 TV 광고 지출 간의 상관 관계를 계산하려면 빈 셀을 선택하고 입력합니다.
=correl(A2:A201, B2:B201)
이 수식은 Excel에서 A2:A201의 판매 수익 데이터와 B2:B201의 TV 광고 지출 데이터 간의 상관 관계를 계산하도록 지시합니다. 다음으로, 라디오의 판매 수익과 광고 지출 간의 상관 관계를 계산하려면 다음 수식을 사용합니다.
=CORREL(A2:A201, C2:C201)
이렇게 하면 A2:A201의 판매 수익 데이터와 C2:C201의 라디오 광고 지출 간의 상관 계수를 얻을 수 있습니다.
첫 번째 수식이 0.78의 상관 계수를 반환하여 TV 광고 지출과 판매 수익 간에 강한 양의 상관 관계가 있음을 나타낸다고 가정해 보겠습니다. 두 번째 수식은 0.576의 상관 계수를 반환하며, 이는 라디오 광고 지출과 판매 수익 간에 약한 양의 상관 관계가 있음을 나타냅니다.
분산형 차트로 상관관계 시각화하기
Correl 함수는 상관 계수에 대한 숫자 값을 제공하지만, 때로는 시각적으로 표현하는 것이 더 효과적일 수 있습니다. 변수 간의 관계를 시각화하기 위해 분산형 차트를 만들어 보겠습니다.
다시 세 가지 데이터 집합으로 작년의 데이터를 분석하는 영업 관리자의 이전 예를 생각해 보겠습니다(TV 광고 예산($), 라디오 광고 예산($) 및 매출($)). 이 예에 대한 분산형 차트를 만들려면 다음과 같이 합니다.
- 헤더를 포함하여 TV 광고 예산 및 판매 데이터가 포함된 데이터 범위를 선택합니다. 이 예제에서 TV 광고 예산 데이터는 B 열에 있고 판매 데이터는 A 열의 2행부터 201행까지에 있습니다.
- 데이터를 선택한 후 Excel 리본의 삽입 탭으로 이동합니다.
- 차트 섹션에서 X Y(분산형)를 클릭합니다.
- Excel에서 선택한 데이터를 기반으로 분산형 차트가 자동으로 만들어집니다. 판매 데이터는 X축에, TV 광고 예산 데이터는 Y축에 표시됩니다. 더 나은 서식을 위해 축 제목을 추가할 수 있습니다.
- 라디오 광고 예산 데이터를 차트에 추가하려면 차트를 우클릭하고 드롭다운 메뉴에서 데이터 선택을 클릭합니다.
- 데이터 소스 선택 창의 범례 항목(시리즈) 아래에서 추가를 클릭합니다.
- 시리즈 이름에 라디오 광고 예산이 포함된 셀을 선택합니다.
- 시리즈 X 값의 경우 매출 데이터 범위(A 열, 2행부터 201행까지)를 선택합니다.
- 시리즈 Y 값의 경우 라디오 광고 예산 데이터 범위(C 열, 2행부터 201행까지)를 선택합니다.
- 확인을 클릭하여 변경 사항을 적용하고 데이터 소스 선택 창을 닫습니다.
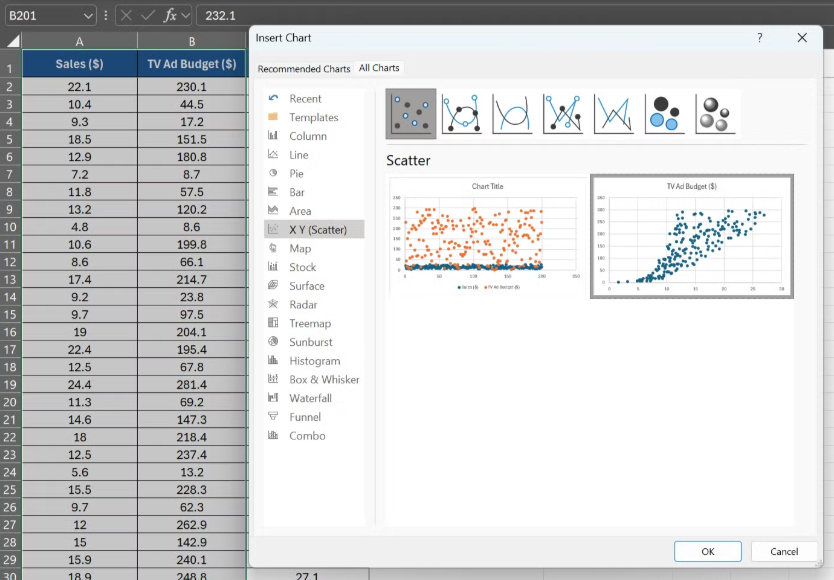
분산형 차트는 TV 광고 예산과 매출 간의 관계와 라디오 광고 예산과 매출 간의 관계에 대한 두 개의 계열을 표시합니다. 이를 통해 상관 관계를 시각적으로 비교하고 어떤 광고 매체가 매출에 더 큰 영향을 미치는지 확인할 수 있습니다.
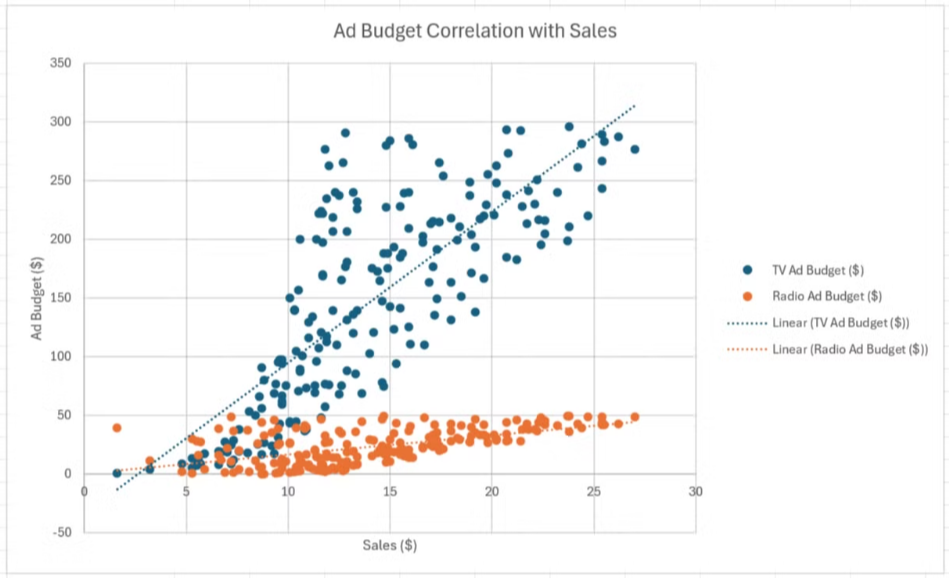
분산형 차트를 사용하면 데이터에서 이상값, 군집, 추세를 쉽게 파악할 수 있습니다. 분산형 차트와 Correl 함수를 결합하면 데이터에 대한 빠른 개요를 얻을 수 있어 Excel 작업을 대폭 줄일 수 있습니다.
CORREL 함수를 다른 Excel 도구와 결합하기
Correl 함수는 그 자체로도 강력한 도구이지만, 다른 Excel 기능과 결합하면 더욱 강력해집니다. 상관관계 분석을 향상시킬 수 있는 두 가지 주요 도구는 피벗 테이블과 XLMiner 분석 도구팩입니다.
Excel의 피벗 테이블을 사용하면 대규모 데이터 세트를 빠르게 요약하고 분석할 수 있습니다. 피벗테이블을 사용하면 변수 간의 상관관계를 쉽게 계산하고 여러 차원에 걸친 추세를 파악할 수 있습니다.
예를 들어, 지역과 제품 카테고리별로 분류된 판매 데이터가 있다고 가정하면 피벗 테이블을 사용하여 판매와 가격, 광고비 또는 고객 인구 통계와 같은 다양한 요인 간의 상관관계를 지역과 카테고리의 각 조합에 대해 계산할 수 있습니다.
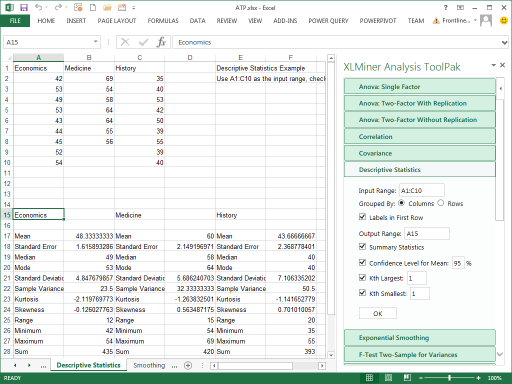
XLMiner 분석 도구팩은 상관관계를 포함한 고급 통계 기능을 제공하는 애드인입니다. 상관관계 함수는 두 변수 간의 상관관계를 계산하는 반면, XLMiner 분석 툴팩의 상관관계 도구는 전체 데이터 세트에 대한 상관관계를 한 번에 계산할 수 있습니다.
마치며
Correl 함수는 데이터의 관계를 분석하여 더 깊은 인사이트를 얻을 수 있는 강력한 도구입니다. 그러나 시간 경과에 따른 데이터를 분석하고 싶다면 Excel의 Trend 함수도 훌륭한 도구입니다. 이와 관련해서는 [여기]를 참고하세요.




'Excel' 카테고리의 다른 글
| Excel 성능을 높이고 로드 시간을 단축하는 8가지 방법 (5) | 2025.03.27 |
|---|---|
| Word나 Excel 파일의 두 곳에서 동시에 작업하는 방법 (4) | 2025.03.25 |
| Excel 작업 속도를 높이기 위한 8가지 방법 (5) | 2025.03.19 |
| Excel에서 마감일과 종속성을 관리하는 8가지 수식 (3) | 2025.03.17 |
| Excel 필수 자동화 도구 10가지 (6) | 2025.03.16 |