들어가기 전에
자르기를 사용하면 PDF의 특정 부분을 추출하여 다른 목적으로 사용할 수 있습니다. 예를 들어 이미지, 차트 또는 더 큰 문서에서 발췌한 내용을 잘라 새 프리젠테이션이나 보고서에 통합 가능합니다. Python을 사용하여 PDF 페이지를 자르는 방법을 소개합니다.

※ 이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: How to Crop PDF Files with Python
- URL: https://medium.com/@alice.yang_10652/how-to-crop-pdf-files-with-python-5bfa99355618
PDF 파일 자르기를 위한 파이썬 라이브러리
Python에서 PDF 파일을 자르는 작업을 처리하기 위한 Python용 라이브러리로 Spire.PDF를 사용하겠습니다. Spire.PDF는 Python 애플리케이션 내에서 PDF 파일을 생성, 읽기, 편집, 변환할 수 있도록 설계된 기능이 풍부하고 사용자 친화적인 라이브러리입니다. 다음 pip 명령을 사용하여 PyPI에서 Python용 Spire.PDF를 설치할 수 있습니다.
pip install Spire.Pdf
Python용 Spire.PDF가 이미 설치되어 있고 최신 버전으로 업그레이드하려면 다음 pip 명령을 사용합니다.
pip install --upgrade Spire.Pdf
설치에 대한 자세한 내용은 [여기]에서 확인할 수 있습니다.
파이썬으로 PDF의 특정 페이지 자르기
PdfDocument.Pages[index] 속성을 사용하여 PDF 파일 내의 특정 페이지에 액세스할 수 있습니다. 그런 다음 PdfPageBase.CropBox 속성을 사용하여 특정 영역으로 잘라낼 수 있습니다.
다음 코드는 PDF 파일에서 특정 페이지를 잘라내어 별도의 PDF 파일로 저장하는 방법을 설명합니다.
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
input_pdf = "Test.pdf"
output_pdf = "CropPage.pdf"
# Initialize an instance of the PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile(input_pdf)
# Get the first page by its index
page = pdf.Pages[0]
# Crop the page to the specified area
page.CropBox = RectangleF(PointF(30.0, 280.0),SizeF(552.0, 220.0))
# Initialize another instance of the PdfDocument class to create a new PDF file
new_pdf = PdfDocument()
# Insert the cropped page into the new PDF file
new_pdf.InsertPage(pdf, 0, 0)
# Save the new PDF file
new_pdf.SaveToFile(output_pdf)
new_pdf.Close()
pdf.Close()
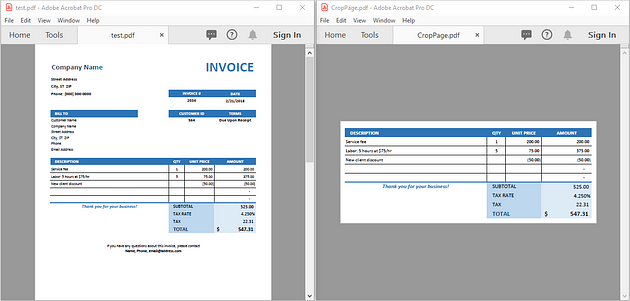
파이썬으로 PDF의 모든 페이지 자르기
PDF의 모든 페이지를 자르려면 문서의 페이지를 반복한 다음 PdfPageBase.CropBox 속성을 사용하여 각 페이지를 특정 영역으로 자릅니다.
다음 코드는 PDF 파일의 모든 페이지를 자르고 그 결과를 Python에서 새 PDF 파일로 저장하는 방법을 설명합니다.
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
input_pdf = "Test.pdf"
output_pdf = "CropAllPages.pdf"
# Initialize an instance of the PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile(input_pdf)
# Iterate through all pages in the file
for i in range(pdf.Pages.Count):
# Get the current page by its index
page = pdf.Pages[i]
# Crop the page to the specified area
page.CropBox = RectangleF(PointF(30.0, 280.0),SizeF(552.0, 220.0))
# Save the result to a new PDF file
pdf.SaveToFile(output_pdf)
pdf.Close()파이썬으로 PDF 페이지를 이미지, HTML로 자르기
경우에 따라 자른 PDF 페이지를 이미지, HTML 파일 등 다른 형식의 파일로 저장하여 나중에 사용해야 할 수도 있습니다. 페이지를 이미지로 저장하려면 PdfDocument.SaveAsImage(pageIndex) 메서드를 사용합니다. 페이지를 HTML 파일이나 다른 형식의 파일로 저장하려면 PdfDocument.SaveToFile(fileName, fileFormat) 메서드를 사용합니다.
다음 코드는 PDF 파일에서 특정 페이지를 잘라 파이썬에서 이미지 파일로 저장하는 방법을 설명합니다.
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
input_pdf = "Test.pdf"
output_image = "CropPage.png"
# Initialize an instance of the PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile(input_pdf)
# Get the first page by its index
page = pdf.Pages[0]
# Crop the page to the specified area
page.CropBox = RectangleF(PointF(30.0, 280.0), SizeF(552.0, 220.0))
# Convert the first page to an image
with pdf.SaveAsImage(0) as imageS:
# Save the image as a PNG file
imageS.Save(output_image)
pdf.Close()
다음 코드는 PDF 파일에서 특정 페이지를 자르고 Python에서 HTML 파일로 저장하는 방법을 설명합니다.
from spire.pdf.common import *
from spire.pdf import *
# Specify the input and output file paths
input_pdf = "Test.pdf"
output_html = "CropPage.html"
# Initialize an instance of the PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile(input_pdf)
# Get the first page by its index
page = pdf.Pages[0]
# Crop the page to the specified area
page.CropBox = RectangleF(PointF(30.0, 280.0),SizeF(552.0, 220.0))
# Initialize another instance of the PdfDocument class to create a new PDF file
new_pdf = PdfDocument()
# Insert the cropped page to the new PDF file
new_pdf.InsertPage(pdf, 0, 0)
# Save the result to an HTML file
new_pdf.SaveToFile(output_html, FileFormat.HTML)
new_pdf.Close()
pdf.Close()
마치며
이상으로, Python과 Python용 Spire.PDF 라이브러리를 사용해 PDF 페이지를 자르는 방법에 대해 알아보았습니다. Spire.PDF 라이브러리는 텍스트 추출, 이미지 추출, 표 추출, 양식 채우기 등 다양한 PDF 조작 기능을 제공합니다. 라이브러리의 모든 기능을 살펴보려면 라이브러리 설명서를 참조하세요.



'Python' 카테고리의 다른 글
| 파이썬을 사용하여 PowerPoint에서 테이블 만들기(또는 추출하기) (0) | 2024.07.21 |
|---|---|
| 파이썬에서 PDF 테이블을 텍스트, Excel 및 CSV로 추출하는 방법 (0) | 2024.07.20 |
| 파이썬 코드 수준을 높이는 7가지 간단한 방법 (0) | 2024.07.13 |
| 파이썬을 사용하여 Excel 데이터를 추출하는 6가지 코드 (0) | 2024.07.07 |
| 파이썬으로 Excel 파일을 읽으시나요? 여기 빠른 방법이 있습니다 (0) | 2024.07.06 |