들어가기 전에
데이터 구조에 따라 PDF 파일에서 테이블 데이터를 추출하는 것은 어려운 작업이 될 수 있습니다. 단순한 텍스트 추출과 달리 테이블은 테이블 구조와 행과 열 간의 관계를 유지하기 위해 신중하게 처리해야 합니다. 파이썬을 사용하여 PDF 테이블을 텍스트, Excel 및 CSV로 추출하는 방법을 소개합니다.

※ 이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: Extract PDF Tables to Text, Excel, and CSV in Python
- URL: https://medium.com/@alice.yang_10652/extract-pdf-tables-to-text-excel-and-csv-in-python-53fdbf3fad91
PDF 표를 텍스트, Excel, CSV로 추출하는 파이썬 라이브러리
PDF 표에서 텍스트, 엑셀, CSV 파일로 데이터를 추출하려면 Python용 Spire.PDF와 Python용 Spire.XLS 라이브러리를 사용할 수 있습니다. Python용 Spire.PDF는 PDF에서 표 데이터를 추출하는 데 주로 사용되며, Python용 Spire.XLS는 추출된 표 데이터를 Excel 및 CSV 파일로 저장하는 데 주로 사용됩니다.
프로젝트의 터미널에서 다음 pip 명령을 실행하여 Python용 Spire.PDF와 Python용 Spire.XLS를 설치할 수 있습니다.
pip install Spire.Pdf
pip install Spire.Xls
Python용 Spire.PDF 및 Python용 Spire.XLS가 이미 설치되어 있고 최신 버전으로 업그레이드하려면 다음 pip 명령을 사용하세요.
pip install --upgrade Spire.Pdf
pip install --upgrade Spire.Xls
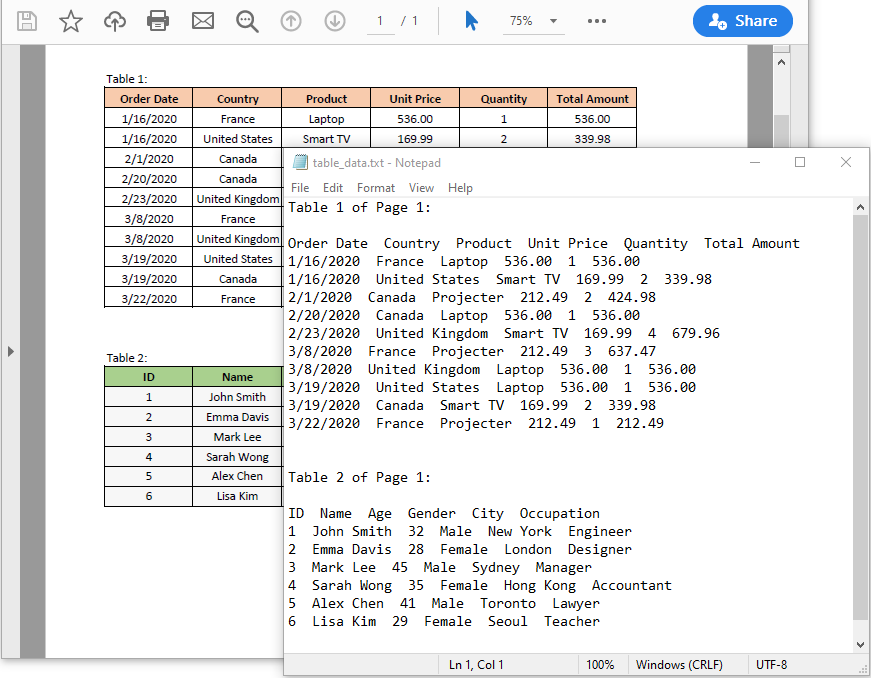
파이썬에서 PDF 표를 텍스트로 추출하기
Python용 Spire.PDF에서 제공하는 PdfTableExtractor.ExtractTable(pageIndex: int) 함수를 사용하면 PDF 내의 표에 액세스할 수 있습니다. 액세스한 후에는 PdfTable.GetText(rowIndex: int, columnIndex: int) 함수를 사용하여 테이블에서 데이터를 쉽게 검색할 수 있습니다. 그런 다음 검색된 데이터를 텍스트 파일에 저장하여 나중에 사용할 수 있습니다.
아래 예는 Python과 Python용 Spire.PDF를 사용하여 PDF 파일에서 표 데이터를 추출하고 결과를 텍스트 파일에 저장하는 방법을 보여줍니다.
from spire.pdf import *
from spire.xls import *
# Define an extract_table_data function to extract table data from PDF
def extract_table_data(pdf_path):
# Create an instance of the PdfDocument class
doc = PdfDocument()
try:
# Load a PDF document
doc.LoadFromFile(pdf_path)
# Create a list to store the extracted table data
table_data = []
# Create an instance of the PdfTableExtractor class
extractor = PdfTableExtractor(doc)
# Iterate through the pages in the PDF document
for page_index in range(doc.Pages.Count):
# Get tables within each page
tables = extractor.ExtractTable(page_index)
if tables is not None and len(tables) > 0:
# Iterate through the tables
for table_index, table in enumerate(tables):
row_count = table.GetRowCount()
col_count = table.GetColumnCount()
table_data.append(f"Table {table_index + 1} of Page {page_index + 1}:\n")
# Extract data from each table and append the data to the table_data list
for row_index in range(row_count):
row_data = []
for column_index in range(col_count):
data = table.GetText(row_index, column_index)
row_data.append(data.strip())
table_data.append(" ".join(row_data))
table_data.append("\n")
return table_data
except Exception as e:
print(f"Error occurred: {str(e)}")
return None
# Define a save_table_data_to_text function to save the table data extracted from a PDF to a text file
def save_table_data_to_text(table_data, output_path):
try:
with open(output_path, "w", encoding="utf-8") as file:
file.write("\n".join(table_data))
print(f"Table data saved to '{output_path}' successfully.")
except Exception as e:
print(f"Error occurred while saving table data: {str(e)}")
# Example usage
pdf_path = "Tables.pdf"
output_path = "table_data.txt"
data = extract_table_data(pdf_path)
if data:
save_table_data_to_text(data, output_path)
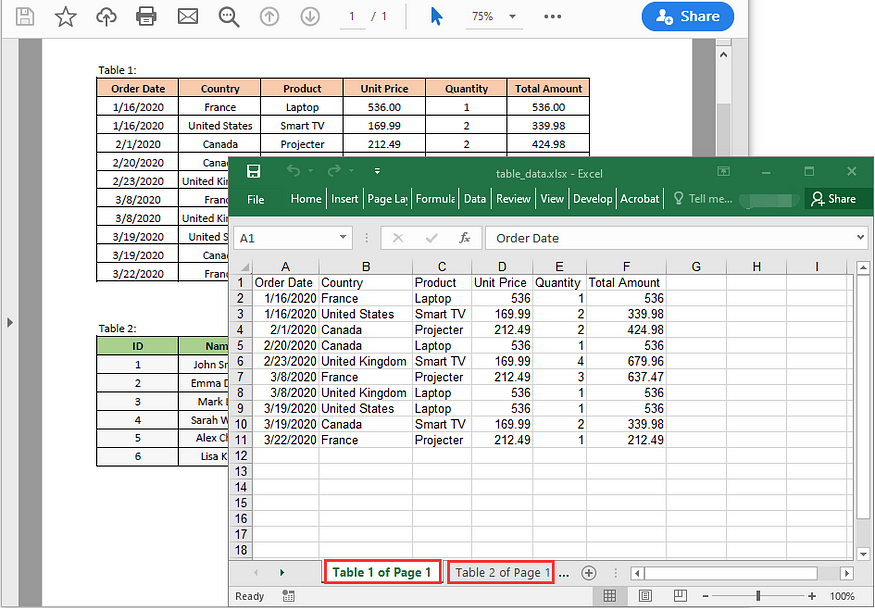
파이썬에서 PDF 표를 Excel로 추출하기
PDF 표를 Excel로 추출하는 것은 표 형식 데이터에 대한 추가 분석, 계산 또는 시각화를 수행해야 할 때 유용합니다. 파이썬용 Spire.PDF를 파이썬용 Spire.XLS와 함께 사용하면 PDF 표에서 Excel 워크시트로 데이터를 쉽게 내보낼 수 있습니다.
아래 예는 Python용 Spire.PDF 및 Python용 Spire.XLS를 사용하여 PDF 테이블에서 Python의 Excel 워크시트로 데이터를 내보내는 방법을 보여줍니다.
from spire.pdf import *
from spire.xls import *
# Define a function to extract data from PDF tables to Excel
def extract_table_data_to_excel(pdf_path, xls_path):
# Create an instance of the PdfDocument class
doc = PdfDocument()
try:
# Load a PDF document
doc.LoadFromFile(pdf_path)
# Create an instance of the PdfTableExtractor class
extractor = PdfTableExtractor(doc)
# Create an instance of the Workbook class
workbook = Workbook()
# Remove the default 3 worksheets
workbook.Worksheets.Clear()
# Iterate through the pages in the PDF document
for page_index in range(doc.Pages.Count):
# Extract tables from each page
tables = extractor.ExtractTable(page_index)
if tables is not None and len(tables) > 0:
# Iterate through the extracted tables
for table_index, table in enumerate(tables):
# Create a new worksheet for each table
worksheet = workbook.CreateEmptySheet()
# Set the worksheet name
worksheet.Name = f"Table {table_index + 1} of Page {page_index + 1}"
row_count = table.GetRowCount()
col_count = table.GetColumnCount()
# Extract data from the table and populate the worksheet
for row_index in range(row_count):
for column_index in range(col_count):
data = table.GetText(row_index, column_index)
worksheet.Range[row_index + 1, column_index + 1].Value = data.strip()
# Auto adjust column widths of the worksheet
worksheet.Range.AutoFitColumns()
# Save the workbook to the specified Excel file
workbook.SaveToFile(xls_path, ExcelVersion.Version2013)
except Exception as e:
print(f"Error occurred: {str(e)}")
# Example usage
pdf_path = "Tables.pdf"
xls_path = "table_data.xlsx"
extract_table_data_to_excel(pdf_path, xls_path)
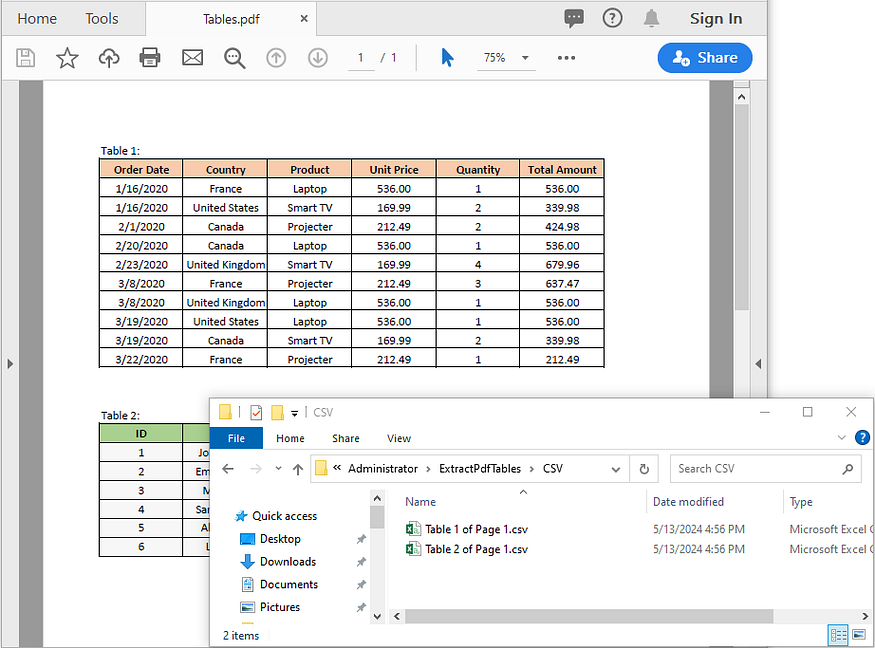
파이썬에서 PDF 표를 CSV로 추출하기
CSV는 스프레드시트 소프트웨어, 데이터베이스, 프로그래밍 언어, 데이터 분석 도구에서 열고 처리할 수 있는 범용 형식입니다. PDF 표를 CSV 형식으로 추출하면 데이터에 쉽게 액세스하고 다양한 애플리케이션 및 도구와 호환할 수 있습니다.
아래 예는 Python용 Spire.PDF와 Python용 Spire.XLS를 사용하여 Python에서 PDF 표의 데이터를 CSV 파일로 내보내는 방법을 보여줍니다.
from spire.pdf import *
from spire.xls import *
# Define a function to extract data from PDF tables to CSV
def extract_table_data_to_csv(pdf_path, csv_directory):
# Create an instance of the PdfDocument class
doc = PdfDocument()
try:
# Load a PDF document
doc.LoadFromFile(pdf_path)
# Create an instance of the PdfTableExtractor class
extractor = PdfTableExtractor(doc)
# Create an instance of the Workbook class
workbook = Workbook()
# Remove the default 3 worksheets
workbook.Worksheets.Clear()
# Iterate through the pages in the PDF document
for page_index in range(doc.Pages.Count):
# Extract tables from each page
tables = extractor.ExtractTable(page_index)
if tables is not None and len(tables) > 0:
# Iterate through the extracted tables
for table_index, table in enumerate(tables):
# Create a new worksheet for each table
worksheet = workbook.CreateEmptySheet()
row_count = table.GetRowCount()
col_count = table.GetColumnCount()
# Extract data from the table and populate the worksheet
for row_index in range(row_count):
for column_index in range(col_count):
data = table.GetText(row_index, column_index)
worksheet.Range[row_index + 1, column_index + 1].Value = data.strip()
csv_name = csv_directory + f"Table {table_index + 1} of Page {page_index + 1}" + ".csv"
# Save each worksheet to a separate CSV file
worksheet.SaveToFile(csv_name, ",", Encoding.get_UTF8())
except Exception as e:
print(f"Error occurred: {str(e)}")
# Example usage
pdf_path = "Tables.pdf"
csv_directory = "CSV/"
extract_table_data_to_csv(pdf_path, csv_directory)
마치며
파이썬을 사용하여 PDF 테이블의 데이터를 텍스트, Excel 및 CSV 파일로 검색하는 방법에 대해 알아보았습니다. 이 정보가 도움이 되기를 바랍니다.



'Python' 카테고리의 다른 글
| 파이썬을 사용하여 다양한 소스의 데이터를 Excel로 가져오기 (0) | 2024.08.03 |
|---|---|
| 파이썬을 사용하여 PowerPoint에서 테이블 만들기(또는 추출하기) (0) | 2024.07.21 |
| 파이썬으로 PDF 파일을 자르는 방법 (0) | 2024.07.14 |
| 파이썬 코드 수준을 높이는 7가지 간단한 방법 (0) | 2024.07.13 |
| 파이썬을 사용하여 Excel 데이터를 추출하는 6가지 코드 (0) | 2024.07.07 |