들어가기 전에
Excel의 다양성은 여러 분야에서 선호되며, 데이터를 관리하고 분석하기 위한 핵심 도구입니다. 그러나 대규모 데이터 세트로 작업하거나 Excel에서 반복적인 작업을 수동으로 수행하는 것은 시간이 많이 걸리고 오류가 발생하기 쉽습니다. 파이썬을 사용하여 Excel 스프레드시트를 효율적으로 작업하는 방법을 소개합니다.

※ 이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: Working With Excel Spreadsheets in Python
- URL: https://gaurav-adarshi.medium.com/working-with-excel-spreadsheets-in-python-2c3c2171879d
환경 설정하기
Excel 파일 작업을 시작하기 전에 Python 환경을 설정합니다.
파이썬 및 필수 라이브러리 설치
먼저 컴퓨터에 Python이 설치되어 있는지 확인합니다. 공식 Python 웹사이트에서 다운로드할 수 있습니다. Python을 설치한 후에는 Excel 파일 작업에 도움이 되는 몇 가지 라이브러리를 설치해야 합니다. 명령 프롬프트 또는 터미널을 열고 실행합니다.
pip install pandas openpyxl xlrd xlwt xlsxwriter
가상 환경 설정하기
프로젝트를 위한 가상 환경을 만드는 것이 좋습니다. 이렇게 하면 종속성을 관리하고 프로젝트를 체계적으로 관리할 수 있습니다. 다음 명령을 실행하세요.
python -m venv excel_env
source excel_env/bin/activate
# On Windows use `excel_env\Scripts\activate`bin/activate
# On Windows use `excel_env\Scripts\activate`
설치 확인
모든 것이 올바르게 설정되었는지 확인하려면 Python 스크립트를 만들고 다음 코드를 추가합니다.
import pandas as pd
import openpyxl
import xlrd
import xlwt
import xlsxwriter
print("Libraries installed successfully")

스크립트를 실행합니다. "라이브러리가 성공적으로 설치되었습니다."라는 메시지가 표시되면 준비가 완료된 것입니다.
Excel 파일 읽기
가장 일반적인 작업 중 하나는 Excel 파일에서 데이터를 읽는 것입니다. 판다 라이브러리를 사용하면 이 작업이 쉬워집니다.
Pandas를 사용해 Excel 파일 읽기
Excel 파일을 읽으려면 pandas의 read_excel 함수를 사용합니다.
import pandas as pd
# Read a single sheet
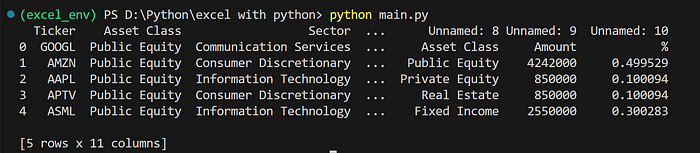
df = pd.read_excel('sample.xlsx', sheet_name='Allocation')
print(df.head())
# Read multiple sheets
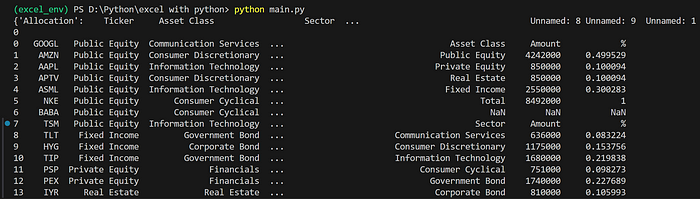
sheets = pd.read_excel('sample.xlsx', sheet_name=['Allocation', 'Holding'])
print(sheets)
다양한 파일 형식 처리하기
동일한 함수를 사용하여 .xls 파일과 .xlsx 파일을 모두 읽을 수 있습니다.
# Reading .xls file
df_xls = pd.read_excel('sample.xls')
# Reading .xlsx file
df_xlsx = pd.read_excel('sample.xlsx')
Excel 파일에 쓰기
Pandas를 사용하면 Excel 파일에 데이터를 쉽게 쓸 수 있습니다.
새 Excel 파일 만들기
새 Excel 파일을 만들고 여기에 데이터를 쓰는 방법은 다음과 같습니다.
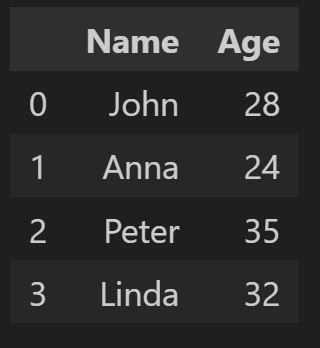
# Create a DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'], 'Age': [28, 24, 35, 32]}
df = pd.DataFrame(data)
# Write DataFrame to Excel
df.to_excel('output.xlsx', index=False)
여러 시트에 쓰기
ExcelWriter 개체를 사용하여 여러 시트에 데이터를 쓸 수 있습니다.
with pd.ExcelWriter('output_multi_sheets.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
df.to_excel(writer, sheet_name='Sheet2', index=False)
셀 및 시트 서식 지정
더 고급 서식을 지정하려면 xlsxwriter 라이브러리를 사용할 수 있습니다.
# Create a DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'], 'Age': [28, 24, 35, 32]}
df = pd.DataFrame(data)
# Write DataFrame to Excel with formatting
with pd.ExcelWriter('formatted_output.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
# Get the xlsxwriter workbook and worksheet objects.
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Add a format.
format1 = workbook.add_format({'num_format': '0.00'})
# Set the column width and format.
worksheet.set_column('B:B', 18, format1)
기존 Excel 파일 수정
기존 Excel 파일을 데이터프레임으로 읽고 변경한 다음 다시 저장하여 수정할 수도 있습니다.
기존 파일에 새 데이터 추가
기존 Excel 파일에 새 데이터를 추가하는 방법은 다음과 같습니다.
# Load existing file
df_existing = pd.read_excel('output.xlsx')
# New data
new_data = {'Name': ['Chris', 'Sarah'], 'Age': [22, 30]}
df_new = pd.DataFrame(new_data)
# Append new data
df_combined = df_existing._append(df_new, ignore_index=True)
# Save to the same file
df_combined.to_excel('output.xlsx', index=False)
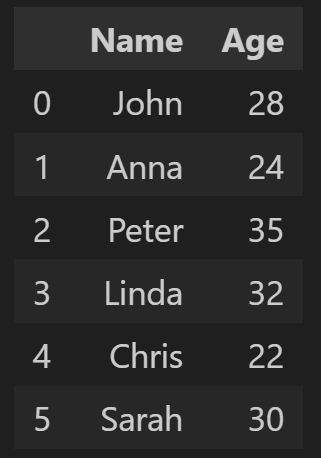
셀 값 수정하기
특정 셀 값을 수정하려면 셀을 찾아 해당 값을 업데이트합니다.
# Load existing file
df = pd.read_excel('output.xlsx')
# Modify a cell value
df.at[1, 'Age'] = 30
# Save the changes
df.to_excel('output.xlsx', index=False)
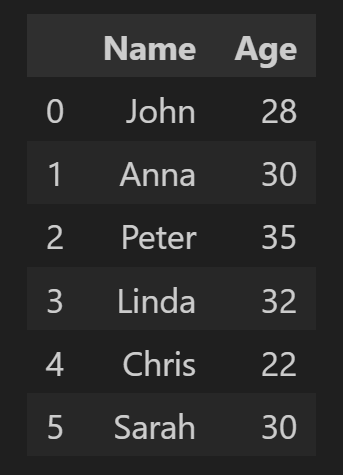
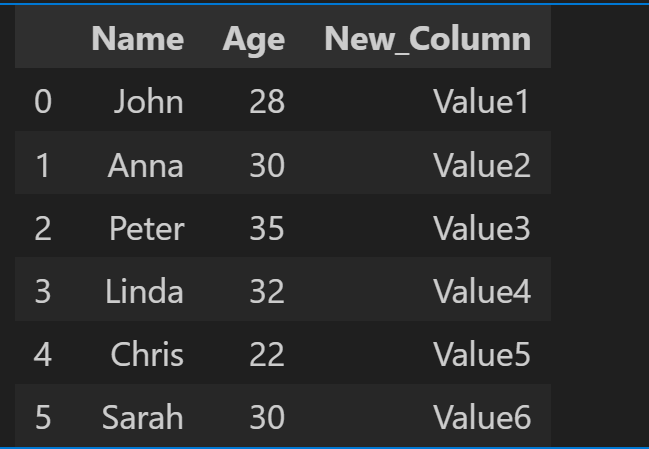
행/열 삽입 및 삭제하기
필요에 따라 행과 열을 삽입하거나 삭제할 수 있습니다.
# Load existing file
df = pd.read_excel('excels files/output.xlsx')
# Insert a new column
df['New_Column'] = ['Value1', 'Value2', 'Value3', 'Value4', 'Value5', 'Value6']
# Save the changes
df.to_excel('excels files/output.xlsx', index=False)
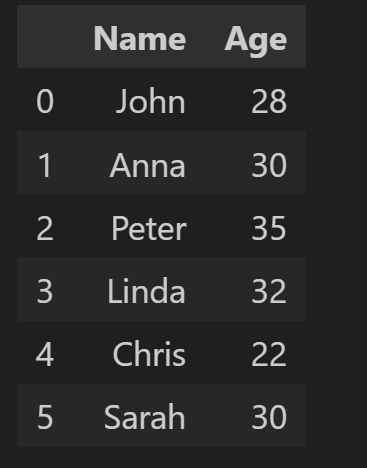
df.drop(columns=['New_Column'], inplace=True)
고급 연산
Python을 사용하면 수식 사용, 차트 만들기, 조건부 서식 적용과 같은 고급 Excel 연산도 가능합니다.
Python을 통해 Excel에서 수식 사용하기
Excel 시트에 수식을 추가할 수 있습니다.
# Create a DataFrame
data = {'Number1': [10, 20, 30], 'Number2': [1, 2, 3]}
df = pd.DataFrame(data)
# Write DataFrame to Excel with formulas
with pd.ExcelWriter('formulas.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Write a formula
worksheet.write_formula('C2', '=A2+B2')
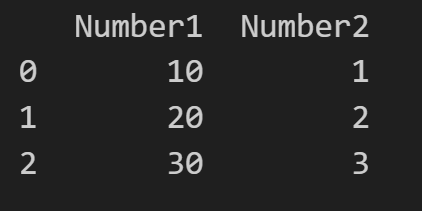
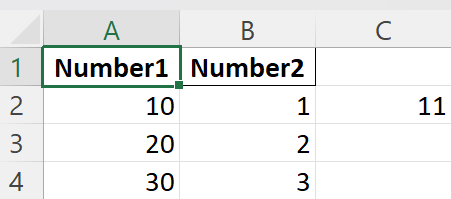
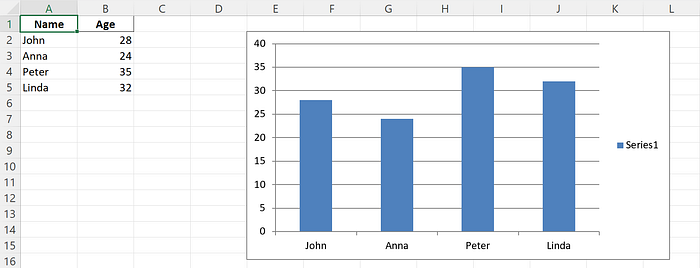
차트 만들기
xlsxwriter를 사용하여 차트를 만들 수 있습니다.
# Create a DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'], 'Age': [28, 24, 35, 32]}
df = pd.DataFrame(data)
# Write DataFrame to Excel and add a chart
with pd.ExcelWriter('charts.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Create a chart object.
chart = workbook.add_chart({'type': 'column'})
# Configure the chart with data series.
chart.add_series({
'categories': ['Sheet1', 1, 0, 4, 0],
'values': ['Sheet1', 1, 1, 4, 1],
})
# Insert the chart into the worksheet.
worksheet.insert_chart('E2', chart)
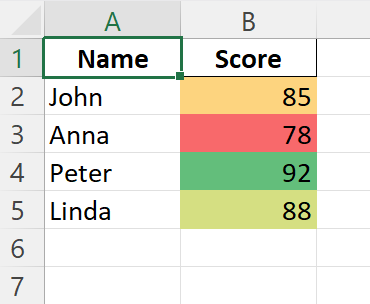
조건부 서식 지정
조건부 서식을 적용하여 데이터를 강조 표시할 수 있습니다.
# Create a DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'], 'Score': [85, 78, 92, 88]}
df = pd.DataFrame(data)
# Write DataFrame to Excel with conditional formatting
with pd.ExcelWriter('conditional_formatting.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Apply conditional formatting
worksheet.conditional_format('B2:B5', {'type': '3_color_scale'})
Excel 작업 자동화
반복적인 작업을 자동화하면 많은 시간을 절약할 수 있습니다.
스크립트로 자동화하기
Python 스크립트를 작성하여 작업을 자동화할 수 있습니다.
import pandas as pd
# Load data
df = pd.read_excel('monthly_report.xlsx')
# Perform some operations
df['Total'] = df['Quantity'] * df['Price']
# Save the updated file
df.to_excel('updated_report.xlsx', index=False)
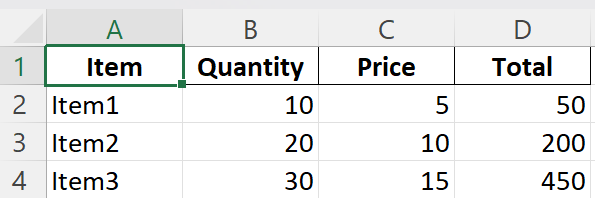
Cron 작업 또는 작업 스케줄러로 스크립트 예약하기
작업 스케줄러(Windows)를 사용하여 이러한 스크립트가 특정 시간에 자동으로 실행되도록 예약할 수 있습니다.
작업 스케줄러 예제(Windows)
- 작업 스케줄러를 엽니다.
- 새 작업을 만듭니다.
- 원하는 시간에 트리거를 매일로 설정합니다.
- 프로그램을 시작하도록 작업을 설정하고 Python 인터프리터 및 스크립트 경로를 선택합니다.
오류 처리 및 디버깅
적절한 오류 처리를 통해 스크립트를 원활하게 실행할 수 있습니다.
일반적인 오류 및 처리 방법
파일을 찾을 수 없음, 잘못된 시트 이름 또는 데이터 유형 불일치 등 몇 가지 일반적인 오류가 있습니다. 시도 예외 블록을 사용하여 이러한 오류를 처리합니다.
try:
df = pd.read_excel('non_existent_file.xlsx')
except FileNotFoundError as e:
print(f"Error: {e}")
디버깅 팁
로깅을 사용하여 오류를 추적하고 스크립트를 디버깅하세요.
import logging
# Configure logging
logging.basicConfig(filename='app.log', level=logging.ERROR)
try:
df = pd.read_excel('non_existent_file.xlsx')
except FileNotFoundError as e:
logging.error(f"Error: {e}")

다른 도구와 통합
Python은 원활한 워크플로우를 위해 Excel을 다양한 다른 도구와 통합할 수 있습니다.
Excel과 데이터베이스 통합
SQLAlchemy와 같은 라이브러리를 사용하여 데이터베이스를 읽고 쓸 수 있습니다.
from sqlalchemy import create_engine
# Create an engine
engine = create_engine('sqlite:///my_database.db')
# Read from database
df = pd.read_sql('SELECT * FROM my_table', engine)
# Write to Excel
df.to_excel('from_database.xlsx', index=False)
df
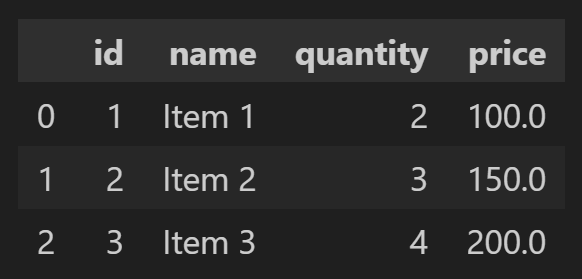
Excel 데이터를 다른 형식으로 내보내기
Excel 데이터를 CSV 또는 JSON으로 쉽게 내보낼 수 있습니다.
# Load data from Excel
df = pd.read_excel('output.xlsx')
# Export to CSV
df.to_csv('output.csv', index=False)
# Export to JSON
df.to_json('output.json', orient='records')
모범 사례 및 팁
모범 사례를 채택하면 효율적이고 유지 관리가 쉬운 코드를 만들 수 있습니다.
깔끔하고 효율적인 코드 작성
- 의미 있는 변수 이름을 사용하세요.
- 반복적인 작업을 위한 함수를 작성하세요.
- 명확성을 위해 코드에 주석을 달아주세요.
대용량 데이터 세트 관리
- 청크사이즈(chunksize) 매개변수를 사용해 대용량 파일을 더 작은 청크로 처리하세요.
- 메모리 문제를 피하기 위해 데이터프레임 작업을 최적화하세요.
데이터 무결성 및 보안 보장
- 처리하기 전에 데이터의 유효성을 검사하세요.
- 민감한 데이터는 유출을 방지하기 위해 신중하게 처리하세요.
라이브러리와 코드를 직접 사용해 볼 수 있는 모든 코드와 엑셀 리소스는 [여기]에서 얻을 수 있습니다.
마치며
파이썬의 Excel 작업 기능은 방대하고 강력합니다. 기본적인 읽기 및 쓰기부터 고급 작업 및 자동화에 이르기까지 Python은 Excel 스프레드시트를 다룰 때 생산성과 효율성을 크게 향상시킬 수 있습니다. pandas, openpyxl, xlsxwriter와 같은 라이브러리를 활용하면 지루한 작업을 자동화하고, 대용량 데이터 세트를 처리하고, Excel을 다른 도구와 원활하게 통합할 수 있습니다. 이 글에서 제공된 지식과 예제를 통해 파이썬에서 Excel 연산을 탐색하고 마스터할 수 있는 충분한 준비를 갖추게 됩니다.


'Python' 카테고리의 다른 글
| 파이썬으로 MS Word 문서 읽는 방법 (1) | 2024.08.18 |
|---|---|
| 데이터 분석가를 위한 웹 스크래핑: 데이터 수집 프로세스 마스터하기 (2) | 2024.08.17 |
| 파이썬으로 Excel에 하이퍼링크 추가, 업데이트, 추출 또는 삭제하기 (2) | 2024.08.10 |
| 파이썬을 사용하여 다양한 소스의 데이터를 Excel로 가져오기 (0) | 2024.08.03 |
| 파이썬을 사용하여 PowerPoint에서 테이블 만들기(또는 추출하기) (0) | 2024.07.21 |