들어가기 전에
Microsoft Word 문서에서 텍스트, 표, 이미지 또는 메타데이터와 같은 특정 데이터를 프로그래밍 방식으로 추출하는 방법을 알고 있으면 문서 처리 작업을 자동화하는 데 유용합니다. 파이썬을 사용하여 Word 문서에서 다양한 유형의 데이터를 읽거나 추출하는 방법을 소개합니다.

※ 이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: How to Read Word Documents with Python
- URL: https://medium.com/@alexaae9/how-to-read-word-documents-with-python-c64f2849839d
워드 문서 읽기를 위한 Python 라이브러리
Spire.Doc은 Microsoft Office Word 문서 작업을 간소화하는 Python 라이브러리입니다. 이 라이브러리를 사용하면 프로그래밍 방식으로 Word 문서를 읽고, 쓰고, 조작할 수 있어 문서 관련 작업을 더 쉽게 자동화할 수 있습니다. 다음 명령을 사용하여 PyPI에서 라이브러리를 설치할 수 있습니다.
pip install Spire.Doc
파이썬에서 특정 단락의 텍스트 추출하기
Spire.Doc을 사용하면 Word 문서의 특정 부분으로 쉽게 작업할 수 있습니다. Document.Sections[index]를 사용하여 섹션에 액세스한 다음 Section.Paragraphs[index]를 사용하여 해당 섹션 내의 단락에 액세스할 수 있습니다. 마지막으로 Paragraph.Text를 사용하여 단락의 텍스트를 가져올 수 있습니다.
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get a specific section
section = doc.Sections[0]
# Get a specific paragraph
paragraph = section.Paragraphs[3]
# Get text of the paragraph
str = paragraph.Text
# Print result
print(str)
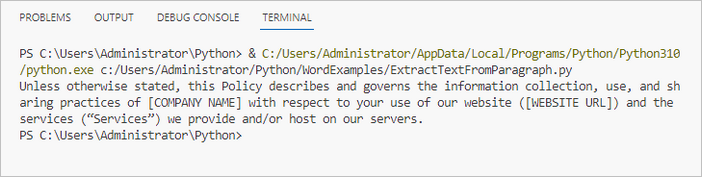
파이썬에서 전체 Word 문서의 텍스트 추출하기
전체 Word 문서의 텍스트를 가져오려면 Document.GetText() 메서드를 사용하면 됩니다.
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get text from the entire document
text = doc.GetText()
# Print result
print(text)
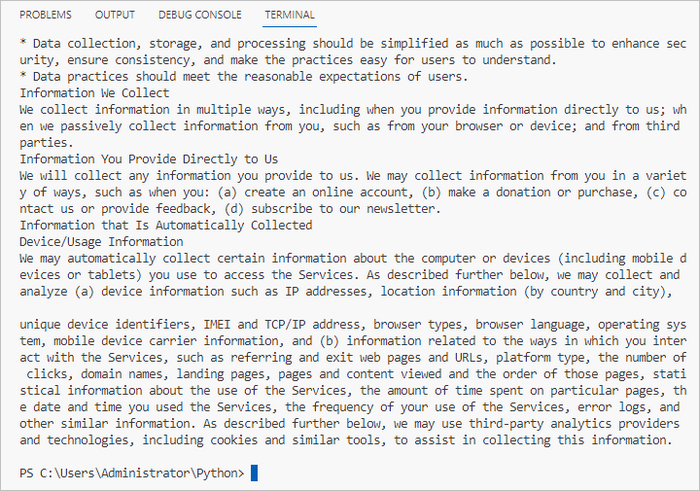
파이썬에서 Word 문서의 표 추출하기
Spire.Doc을 사용하면 Section.Tables를 사용하여 섹션의 표에 액세스할 수 있습니다. 그런 다음 특정 표를 가져와 셀을 검색할 수 있습니다. 각 셀의 텍스트 콘텐츠는 TableCell.Paragraphs.get_Item().Text를 통해 사용할 수 있습니다.
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Iterate through the sections
for i in range(doc.Sections.Count):
# Get a specific section
section = doc.Sections.get_Item(i)
# Get tables from the section
tables = section.Tables
# Iterate through the tables
for j in range(0, tables.Count):
# Get a certain table
table = tables.get_Item(j)
# Declare a variable to store the table data
tableData = ""
# Iterate through the rows of the table
for m in range(0, table.Rows.Count):
# Iterate through the cells of the row
for n in range(0, table.Rows.get_Item(m).Cells.Count):
# Get a cell
cell = table.Rows.get_Item(m).Cells.get_Item(n)
# Get the text in the cell
cellText = ""
for para in range(cell.Paragraphs.Count):
paragraphText = cell.Paragraphs.get_Item(para).Text
cellText += (paragraphText + " ")
# Add the text to the string
tableData += cellText
# Add a new line
tableData += "\n"
# Save the table data to a text file
with open(f"output/WordTable_{i+1}_{j+1}.txt", "w", encoding="utf-8") as f:
f.write(tableData)

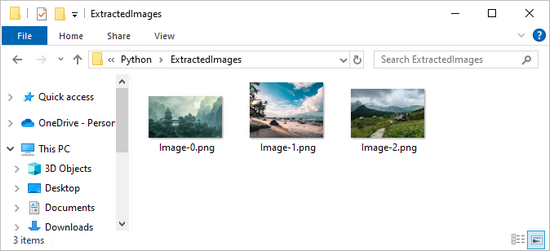
파이썬에서 Word 문서의 이미지 추출하기
Word 문서에서 이미지를 추출하려면 먼저 문서의 하위 개체를 반복해야 합니다. 그런 다음 자식 객체가 DocPicture인지 확인합니다. 그렇다면 DocPicture.ImageBytes를 사용하여 이미지 데이터에 액세스하고 이미지 파일로 저장할 수 있습니다.
import queue
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input2.docx")
# Create a Queue object
nodes = queue.Queue()
nodes.put(doc)
# Create a list
images = []
while nodes.qsize() > 0:
node = nodes.get()
# Loop through the child objects in the doucment
for i in range(node.ChildObjects.Count):
child = node.ChildObjects.get_Item(i)
# Detect if a child object is a picture
if child.DocumentObjectType == DocumentObjectType.Picture:
picture = child if isinstance(child, DocPicture) else None
dataBytes = picture.ImageBytes
# Add the image data to the list
images.append(dataBytes)
elif isinstance(child, ICompositeObject):
nodes.put(child if isinstance(child, ICompositeObject) else None)
# Loop through the images in the list
for i, item in enumerate(images):
fileName = "Image-{}.png".format(i)
with open("ExtractedImages/"+fileName,'wb') as imageFile:
# Write the image to a specified path
imageFile.write(item)
파이썬에서 Word 문서의 메타데이터 추출하기
Spire.Doc을 사용하면 Document.BuiltinDocumentProperties 속성을 사용하여 Word 문서의 기본 제공 문서 속성에 액세스할 수 있습니다. 이를 통해 작성자, 회사, 제목, 제목과 같은 표준 속성에 액세스할 수 있습니다.
from spire.doc import *
from spire.doc.common import *
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Get the built-in properties of the document
builtinProperties = doc.BuiltinDocumentProperties
# Get the value of the built-in properties
properties = [
"Author: " + builtinProperties.Author,
"Company: " + builtinProperties.Company,
"Title: " + builtinProperties.Title,
"Subject: " + builtinProperties.Subject,
"Keywords: " + builtinProperties.Keywords,
"Category: " + builtinProperties.Category,
"Manager: " + builtinProperties.Manager,
"Comments: " + builtinProperties.Comments,
"Hyperlink Base: " + builtinProperties.HyperLinkBase,
"Word Count: " + str(builtinProperties.WordCount),
"Page Count: " + str(builtinProperties.PageCount),
]
# Print result
for i in range(0, len(properties)):
print(properties[i])

'Python' 카테고리의 다른 글
| 파이썬을 사용하여 Excel에서 다양한 유형의 차트 만들기 (11) | 2024.09.14 |
|---|---|
| 파이썬을 사용하여 손쉽게 PDF 분할 및 병합하기 (2) | 2024.09.10 |
| 데이터 분석가를 위한 웹 스크래핑: 데이터 수집 프로세스 마스터하기 (2) | 2024.08.17 |
| 파이썬에서 Excel 스프레드시트 작업하기 (1) | 2024.08.15 |
| 파이썬으로 Excel에 하이퍼링크 추가, 업데이트, 추출 또는 삭제하기 (2) | 2024.08.10 |