들어가기 전에
복잡한 스프레드시트 작업을 한다면 보조 열을 추가하고 수식을 중첩하여 사용하게 되는 경우가 많습니다. 이럴 때 엑셀의 REDUCE를 사용하면 루프가 작동하는 방식처럼 데이터를 반복하여 단계별로 결과를 구축할 수 있습니다. 엑셀의 REDUCE 함수를 사용하여 프로그래밍 언어에서 반복 처리를 하는 것처럼 사용하는 방법을 소개합니다.
REDUCE 함수는 웹용 Excel, Microsoft 365용 Excel, Mac용 Microsoft 365용 Excel에서 사용할 수 있습니다.

이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: Learning REDUCE in Excel completely changed how I use spreadsheet
- URL: https://www.makeuseof.com/reduce-in-excel/
REDUCE 함수가 실제로 하는 일
REDUCE는 데이터 목록을 입력받아 각 항목에 맞춤 계산을 한 번에 하나씩 적용하고, 결과를 결합하는 특수 수식입니다. 궁극적으로 하나의 최종 결과를 반환합니다. 이것이 바로 핵심 아이디어입니다.
REDUCE는 Excel에서 LAMBDA 도우미 함수라고 부르는 함수입니다. 즉, LAMBDA 함수를 사용하여 정의한 계산에 전적으로 의존합니다. LAMBDA는 로직이고 REDUCE는 해당 로직을 실행하는 메커니즘이라고 생각하면 됩니다. 두 함수는 함께 각 계산이 이전 계산을 기반으로 하는 반복적인 단계를 수행합니다.
도우미 열처럼 워크시트에 각 중간 단계를 표시하는 대신, REDUCE는 누산기라고 하는 함수를 사용하여 이러한 단계를 내부에 유지합니다. 기본 구문은 다음과 같습니다.
=REDUCE([initial_value], array, lambda(accumulator, value, body))
| 요소 (argument) | 목적 | 설명 |
| [initial_value] | 축적을 시작할 값 | 합계를 계산할 때는 0부터 시작하고, 텍스트를 입력할 때는 빈 문자열("")을 사용합니다. 기존 값을 수정하려는 경우에는 셀 참조를 사용할 수도 있습니다. |
| array | REDUCE가 순환하는 소스 데이터 | 이 배열의 각 항목은 나타나는 순서대로 하나씩 처리됩니다. |
| [lambda] | 배열의 각 항목에 적용되는 사용자 지정 계산 | 이 함수는 항상 세 개의 변수를 사용합니다. 누산기(종종 A로 표시), 배열의 현재 값(종종 V로 표시), 그리고 계산 본문(예: A + V)입니다. 누산기는 이전 반복의 실행 결과를 저장하고, 값은 현재 처리 중인 항목을 나타냅니다. |
흐름은 간단합니다. 누산기는 초기값으로 시작합니다. REDUCE는 배열의 첫 번째 요소를 가져와 LAMBDA 계산을 적용하고, 그 결과로 누산기를 업데이트합니다. 그런 다음 다음 요소로 이동하여 매번 새로 업데이트된 누산기를 사용하여 이 과정을 반복합니다.
모든 항목이 처리되면 REDUCE는 최종 누산기를 출력합니다. 출력은 LAMBDA가 생성하는 값에 따라 단일 숫자, 텍스트 또는 분산된 배열일 수 있습니다.
이 설정의 장점은 더 이상 시트 전체에 분산된 여러 수식에 의존할 필요가 없다는 것입니다. 모든 작업이 하나의 수식, 하나의 셀에 저장되어 있으므로, 추가 보조 열이나 중간 단계 없이 모든 작업이 처리됩니다.
REDUCE를 사용하는 실용적인 방법
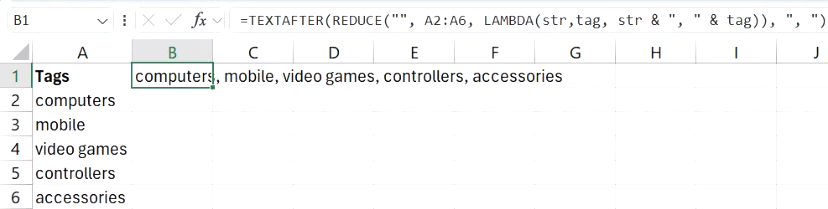
REDUCE는 시간이 지남에 따라 결과가 누적되는 상황, 특히 각 단계가 이전 단계에 의존하는 상황에서 탁월한 성능을 발휘합니다. 하지만 일반적인 목록 작업에도 마찬가지로 유용합니다. 저는 이 함수를 꾸준히 사용하고 있는데, 함수의 작동 방식을 알게 되면 이전에는 보조 열이나 반복되는 수식에 의존했던 곳에도 적용할 수 있는 기회를 발견하게 될 것입니다.
예제 1: 한 번에 여러 독립 항목 계산

개인적으로 가장 좋아하는 기능 중 하나는 목록에서 여러 항목의 발생 횟수를 동시에 세는 것입니다. 주문 위치 열이 있고 파리와 런던에서 발생한 주문의 합계를 알고 싶다고 가정해 보겠습니다. 별도의 COUNTIF 수식을 작성하여 합산하는 대신, 다음과 같이 하나의 표현식으로 모든 것을 처리할 수 있습니다.
=REDUCE(0, {"Paris","London"}, LAMBDA(total, city, total + COUNTIF(A2:A9, city)))
합계를 누적하기 때문에 0부터 시작합니다. 모든 데이터 행을 반복하는 대신, 관심 있는 두 도시, 파리와 런던을 반복합니다. 각 도시에 대해 COUNTIF 함수는 A열에 나타나는 횟수를 확인하고, 그 결과를 누적 합계에 더합니다.
최종 출력은 두 도시의 순서를 합한 단일 숫자입니다. 지리적 범위를 조정해야 할 경우, 중괄호 안의 목록만 수정하면 됩니다. 수식을 재구성할 필요가 없습니다.
예제 2: 혼합 텍스트 문자열에 포함된 수량 합계

REDUCE는 데이터가 명확하지 않을 때도 유용합니다. 주문 열에 'SHIRT(5),' 'PANT(2),' 'HAT(3)'과 같은 항목이 있고, 여기에 품목 이름과 수량이 함께 저장되어 있다고 가정해 보겠습니다. 주문 수량에 관계없이 특정 카테고리(예: SHIRT와 PANT)의 수량을 합산하려는 경우, REDUCE는 다음과 같이 깔끔하게 처리합니다.
=REDUCE(0, {"SHIRT", "PANT"}, LAMBDA(total, category, total + COUNTIF(A2:A7, category & "(*")))
핵심은 와일드카드(*)입니다. 괄호 안의 숫자는 행마다 다르므로, 와일드카드는 'SHIRT(' 또는 'PANT('로 시작하는 모든 텍스트가 합계에 포함되도록 합니다. REDUCE는 각 범주를 순회하며 A2:A7에서 일치하는 모든 항목을 세고 합계를 누적합니다.
결과는 개별 수량과 관계없이 두 품목 유형의 총 개수를 나타내는 단일 값입니다.
예제 3: 보조 없이 행을 분할하고 결과를 세로로 쌓기
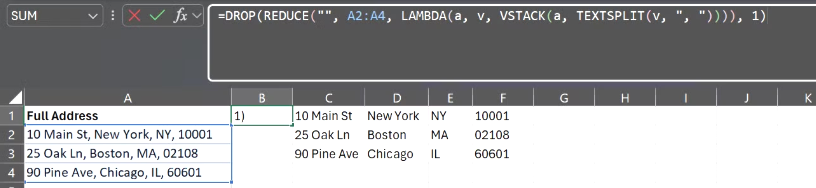
REDUCE가 탁월한 또 다른 영역은 데이터 레이아웃을 변환할 때입니다. 10 Main St, New York, NY, 10001과 같은 형식의 전체 주소 열이 있고, 각 열을 도로명, 도시, 주, 우편번호별로 분리하려고 한다고 가정해 보겠습니다. 보조 열을 사용하거나, 전체 출력을 한 번에 생성할 수 있습니다.
=DROP(REDUCE("", A2:A4, LAMBDA(a, v, VSTACK(a, TEXTSPLIT(v, ", ")))), 1)
이 수식은 빈 문자열을 누산기로 사용합니다. 각 루프에서 TEXTSPLIT은 쉼표와 공백 구분 기호를 사용하여 현재 주소를 필드로 나누고, VSTACK은 해당 필드를 지금까지 생성된 결과 아래에 세로로 추가합니다. 첫 번째 반복에서 누산기가 비어 있기 때문에 앞에 빈 행이 생성되므로, DROP은 맨 위의 마지막 빈 행을 제거하여 깔끔하게 정렬된 분할 주소 테이블을 남깁니다.
이 모든 작업은 단일 도우미 열 없이 수행됩니다. 변환의 모든 단계는 단일 수식에 캡슐화되어 새 주소가 추가됨에 따라 동적으로 확장되는 출력을 생성합니다.
REDUCE는 컨베이어 벨트와 유사합니다. 원시 입력 스트림(배열)을 받고, 각 항목(LAMBDA 함수 본문)에 사용자 지정 변환을 적용한 후, 처리된 각 결과를 계속해서 증가하는 결과(누산기)로 다시 접습니다. 전체 배열이 처리될 때쯤이면 하나의 결과만 남습니다. 워크시트 전체에 걸쳐 모든 중간 단계를 구성하는 대신, 전체 진행 과정은 수식 자체 내에서 단일하고 연속적인 시퀀스로 이루어집니다.
마치며
REDUCE 함수를 사용하기 전에는 작업이 복잡해 보일 때마다 도우미 열을 추가하는 경우가 많습니다. REDUCE 함수를 사용하면 번거로운 보조열의 도움 없이도 하나의 수식으로 해결할 수 있습니다.
'Excel' 카테고리의 다른 글
| Excel에서 EOMONTH 함수를 사용하는 방법 (0) | 2026.02.25 |
|---|---|
| 몇 분 만에 지저분한 Excel 데이터를 아름답게 만드는 방법 5가지 (0) | 2026.02.24 |
| 오늘(2/22 일) 오후에 새로운 콘텐츠가 오픈됩니다 (0) | 2026.02.22 |
| Excel에서 SORT와 SORTBY: 어떤 것을 사용해야 할까요? (1) | 2026.02.20 |
| Excel의 REDUCE 함수는 훌륭하지만 이것보다 더 신뢰하는 오래된 함수 (0) | 2026.02.19 |