들어가기 전에
Excel 통합 문서에서 두 개 이상의 배열을 결합하는 것은 예전에는 복잡하고 지루한 작업이었습니다. 그러나 VSTACK과 HSTACK 함수가 도입되면서 상황이 달라졌습니다. 이들 함수를 사용하여 Excel에서 데이터를 행 방향 또는 열 방향으로 손쉽게 합치는 방법을 소개합니다.
[참고] VSTACK과 HSTACK 함수는 Microsoft 365, 웹 및 모바일용 Excel에서 사용할 수 있습니다.

이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: How to Use the VSTACK and HSTACK Functions in Microsoft Exce
- URL: https://www.howtogeek.com/microsoft-excel-how-to-use-vstack-hstack-functions/
VSTACK 및 HSTACK 함수 기본 구문
VSTACK 함수는 다음 구문을 사용하여 배열을 수직으로 추가합니다.
=VSTACK(a, [b], ... ]
인수 a는 스택의 맨 위에 처음 나타나는 배열이고, 인수 b는 바로 아래에 추가되는 최대 253개의 배열 중 첫 번째입니다.

반면, HSTACK 함수는 배열을 수평으로 추가합니다.
=HSTACK(a, [b], ...)
인수 a는 추가된 결과의 가장 왼쪽 배열이고, 인수 b는 바로 오른쪽에 추가되는 최대 253개의 추가 배열 중 첫 번째입니다.

254개가 넘는 배열을 모두 쌓으려고 하면 "이 함수에 인수를 너무 많이 입력했습니다."라는 메시지가 표시됩니다. VSTACK과 HSTACK 조합을 추가로 중첩하면 이 문제를 해결할 수 있지만, 통합 문서의 성능이 크게 저하될 수 있습니다.
VSTACK과 HSTACK은 동적 배열 함수입니다. 즉, 수식을 입력한 셀에서 결과가 출력되고, 원본 배열의 데이터 변경 사항은 누적 배열에 반영됩니다. 하지만 동적 배열은 Excel 표와 호환되지 않으므로 일반 셀에 수식을 입력해야 합니다.
VSTACK 및 HSTACK 사용 예
Excel의 VSTACK 및 HSTACK 함수를 사용하면 일반 셀 범위, Excel 표 또는 명명된 범위에 데이터를 추가할 수 있습니다.
예를 들어 E1 셀에 다음 수식을 입력합니다.
=VSTACK(A2:C6, A9:C13, A16:C20)
이 수식은 E1 셀에 A2:C6, A9:C13, A16:C20 영역의 세 배열을 수직으로 쌓습니다.

다음 수식은 A2:C6, G2:G6 영역의 데이터를 수평으로 쌓습니다.
=HSTACK(A2:C6, G2:G6)
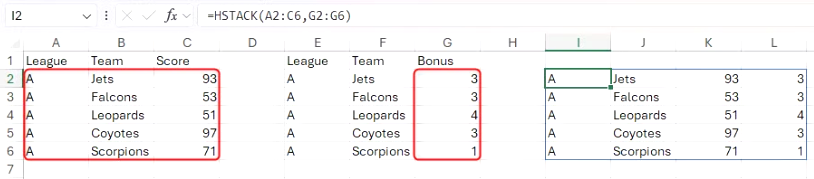
셀 참조 대신 명명된 범위를 사용하면 이해하고 분석하기가 더 쉽고, 마우스를 사용하지 않고도 수식에 명명된 범위를 빠르게 추가할 수 있다는 장점이 있습니다. HSTACK 함수에도 동일한 원리를 적용할 수 있습니다.
위의 모든 예에서 원본 범위에 더 많은 행이나 열이 추가되면 VSTACK과 HSTACK은 이를 인식하지 못합니다. 그러나 원본 데이터가 Excel 표 형식으로 지정된 경우, 추가된 행이나 열은 결과에 추가됩니다. 이는 수식이 설정된 셀 범위가 아닌 표 이름(구조적 참조)을 참조하기 때문입니다.
=VSTACK(T_LgA, T_LgB, T_LgC)

VSTACK과 HSTACK을 사용하여 통합 문서 내 여러 워크시트의 데이터를 추가할 때도 테이블이 유용합니다. 데이터 세트가 별도의 워크시트에 있는 일반 범위에 저장된 경우, 탭 사이를 이동하며 범위를 직접 선택해야 하며, 각 워크시트의 구조가 동일한 경우 3D 참조를 사용해야 합니다.
그러나 Excel 통합 문서의 모든 테이블은 고유한 이름을 가져야 하므로 Excel에서 테이블이 어느 시트에 있는지 지정할 필요가 없습니다. 첫 글자만 입력하고 화살표 키를 사용하여 해당 테이블로 이동한 후 Tab 키를 눌러 확인하면 됩니다.
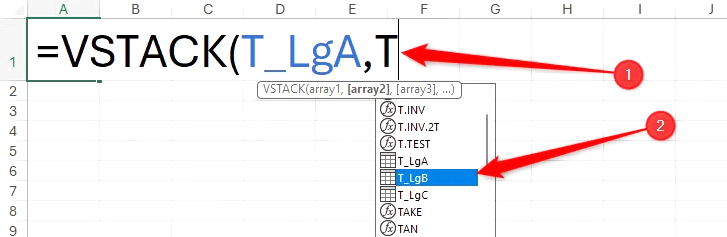
HSTACK 함수에도 같은 개념이 적용됩니다.
VSTACK과 HSTACK 결합
때로는 배열의 일부를 추가하기 위해 단일 수식에서 VSTACK과 HSTACK을 함께 사용해야 할 수도 있습니다. 다음 예에서, 첫 번째 열에 리그, 두 번째 열에 팀, 세 번째 열에 점수, 네 번째 열에 보너스를 넣어 새로운 배열을 만든다고 가정합니다.
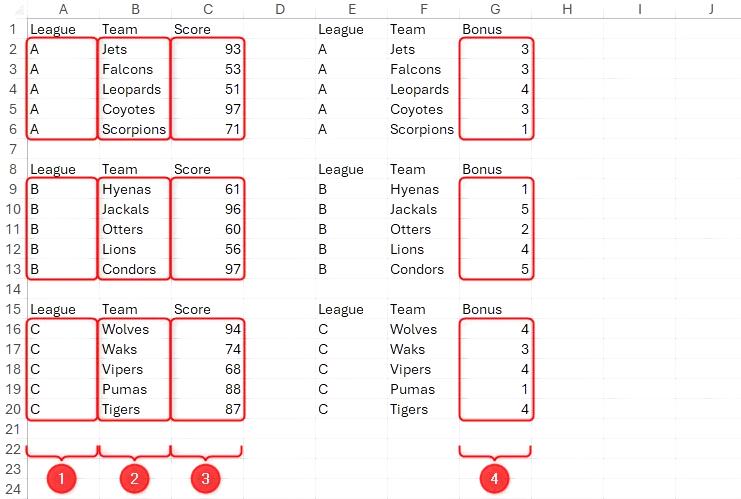
HSTACK 내부에 VSTACK을 중첩하면 이 문제를 해결할 수 있습니다.
=HSTACK(VSTACK(A2:C6, A9:C13, A16:C20), VSTACK(G2:G6, G9:G13, G16:G20))
먼저, A2:C6, A9:C13, A16:C20 셀의 데이터를 세로로 쌓습니다. 그런 다음, G2:G6, G9:G13, G16:G20 셀의 데이터도 같은 방식으로 쌓습니다. 마지막으로, 이 두 개의 VSTACK 배열을 HSTACK을 사용하여 가로로 추가합니다.

VSTACK 내부에 HSTACK을 중첩할 수도 있습니다.
=VSTACK(HSTACK(A2:C6, G2:G6), HSTACK(A9:C13, G9:G13), HSTACK(A16:C20, G16:G20))
이번에는 먼저 HSTACK을 사용하여 A2:C6까지의 셀에 있는 데이터를 G2:G6까지의 셀에 있는 데이터와 합친 다음, 나머지 두 리그에도 동일한 작업을 수행합니다. 마지막으로, 이 세 개의 HSTACK 배열을 VSTACK을 사용하여 세로로 합칩니다.
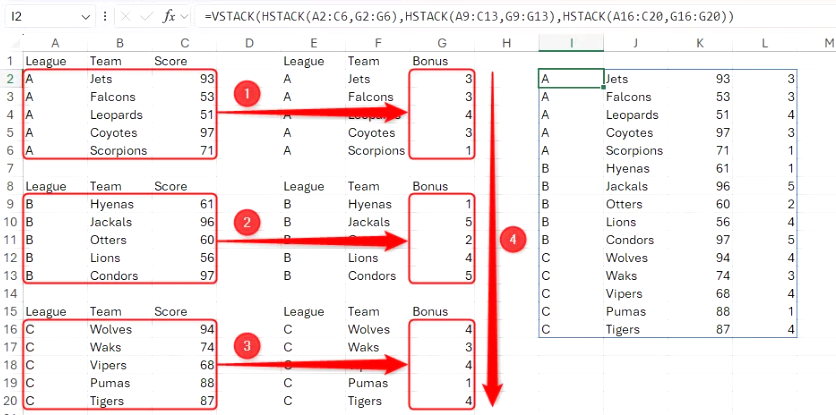
두 함수 중 어떤 함수를 다른 함수 안에 중첩할지는 수직 스택과 수평 스택 중 어떤 스택을 더 많이 수행해야 하는지에 따라 달라집니다. 위 예에서는 수직 스택은 세 개이고 수평 스택은 두 개이므로, VSTACK을 HSTACK 안에 중첩하면 수식이 더 짧아집니다. 하지만 수직 스택보다 수평 스택을 더 많이 수행해야 하는 경우, HSTACK을 VSTACK 안에 중첩하는 것이 좋습니다.
VSTACK 및 HSTACK을 사용하여 다양한 크기의 배열 추가
VSTACK을 사용하여 배열을 세로로 추가할 때, 총 행 수는 선택한 배열의 모든 행 수를 합한 값입니다. 하지만 결과가 차지하는 열 수는 선택한 배열에서 가장 넓은 배열의 열 수와 같습니다.
아래 스크린샷에서 VSTACK을 사용하여 배열을 추가하면, 결과는 높이 15행(추가된 각 배열에 5행씩)과 너비 4열(가장 넓은 추가 배열의 너비)이 됩니다. 그러나 작은 배열들이 가장 큰 배열의 크기에 맞춰 확장되었기 때문에 누락된 값 대신 #N/A가 반환됩니다.
=VSTACK(A2:D6, A9:C13, A16:C20)

결과 VSTACK 배열을 정리하는 한 가지 방법은 전체 수식을 IFNA로 묶고 큰따옴표를 사용하여 빈 문자열을 빈 셀로 바꾸는 것입니다.
=IFNA(VSTACK(A2:D6, A9:C13, A16:C20), "")

마찬가지로 HSTACK을 사용하여 배열을 수평으로 추가할 때, 전체 열 수는 원본 데이터의 열 수에 따라 결정되지만 행 수는 선택한 배열 중 가장 높은 배열의 수와 같습니다. 따라서 배열 높이가 서로 다른 이 예에서, 수식은 작은 배열이 가장 큰 배열에 맞춰 확장되었다는 #N/A 오류를 반환합니다.

이 문제를 해결하려면 HSTACK 수식을 IFNA로 묶고 오류를 큰따옴표로 바꿉니다.
=IFNA(HSTACK(A2:C7, G2:G6), "")
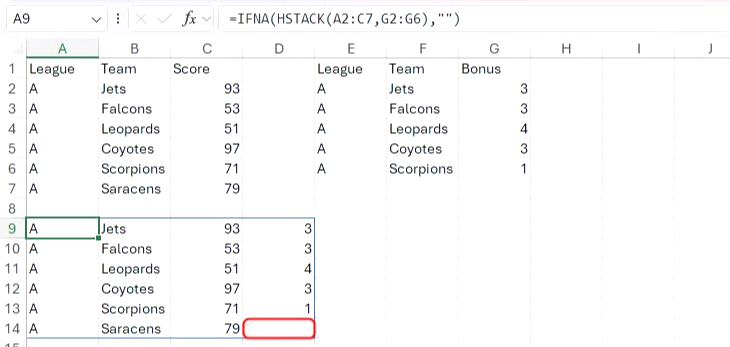
VSTACK 및 HSTACK에서 빈 셀과 0 처리
기본적으로 VSTACK과 HSTACK은 원본 데이터의 공백과 0을 모두 0으로 반환합니다. 이 방식은 어떤 경우에는 이상적일 수 있지만, 데이터에서 공백 셀과 0 값이 서로 다른 의미를 갖는 경우 혼란스러울 수 있습니다.
이 예에서 Coyotes는 실격 처리되었으므로 VSTACK 수식 결과에는 Coyotes 의 점수인 0점이 반영되어야 합니다. 그러나 Leopards의 점수는 아직 입력되지 않았으므로 빈칸으로 남겨두어야 합니다. 그러나 VSTACK 함수를 사용하여 각 리그의 데이터를 세로로 추가하면 두 리그 모두 0으로 표시됩니다.
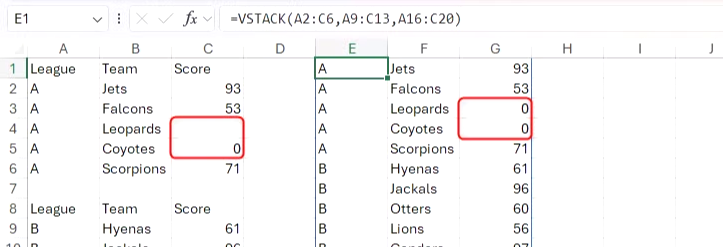
이 문제를 해결하려면 SUBSTITUTE 수식에 VSTACK 또는 HSTACK 함수를 중첩하고 빈 문자열을 빈 문자열로 바꿉니다.
=SUBSTITUTE(VSTACK(A2:C6, A9:C13, A16:C20), "", "")
SUBSTITUTE 함수의 이전 텍스트와 새 텍스트 인수가 모두 빈 문자열인 것이 이상하게 보일 수 있지만, 이 해결책은 잘 작동합니다. 실제로 이제 Coyotes의 점수는 0으로, Leopards의 점수는 빈 문자열로 올바르게 표시됩니다.

VSTACK 출력에 열 헤더 추가
Excel에서 VSTACK을 사용할 때는 항상 열 머리글 없이 데이터를 추가해야 합니다. 그렇지 않으면 머리글이 결과에 반복되어 정렬 및 필터링 중에 데이터의 일부로 계산됩니다.
하지만 열 머리글을 생략할 때 한 가지 문제는 추가된 배열이 불분명해질 수 있다는 것입니다. 이 문제를 해결하려면 수식을 사용하여 원본 데이터의 머리글을 복제합니다. 다음과 같이 입력합니다.
=A1:C1
VSTACK 수식 결과 바로 위에 있는 셀 E1에 원래 헤더가 변경되면 자동으로 업데이트되어 첫 번째 배열 위에 있는 헤더 행을 동적으로 복제합니다.

HSTACK을 사용할 때 행 헤더에도 동일한 방식을 사용할 수 있습니다. 하지만 잘 구조화된 데이터세트는 필드가 열이고 레코드가 행인 경우가 많으므로, 행 헤더가 필요한 경우 데이터를 전치 하고 열 헤더를 사용하는 것을 고려해 보세요.
동일한 원칙이 표에도 적용되지만, 이번에는 셀을 직접 참조하는 대신 머리글 행에 대한 구조화된 참조를 사용할 수 있습니다.
=T_LgA[#Headers]
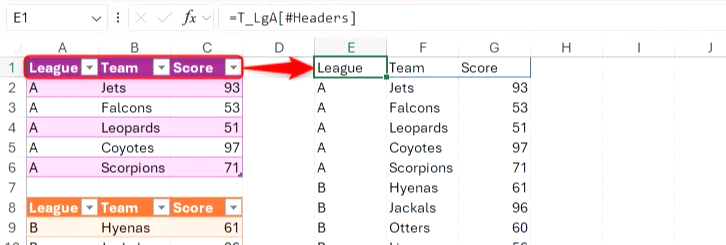
테이블 열 머리글을 참조하는 이점은 더 많은 열이 추가될 경우, 열 머리글에 대한 구조적 참조를 포함하는 수식과 VSTACK 수식 모두에 자동으로 적용된다는 것입니다. 게다가 VSTACK 함수의 결과는 참조된 배열 중 가장 넓은 부분만큼 넓기 때문에 나머지 테이블을 확장하고 새 데이터를 입력할 준비가 된 것입니다.

추가된 VSTACK 배열 정렬
VSTACK 함수의 장점 중 하나는 이전에 별도 범위에 있던 동일한 데이터를 연속된 배열에 추가하여 비교 분석을 보다 효율적으로 수행할 수 있다는 것입니다.
하지만 새로 추가된 배열을 정렬하고 싶다면 어떻게 해야 할까요? 예를 들어, Score 열을 내림차순으로 정렬하면 이 결과의 가치가 훨씬 더 높아질 것입니다.
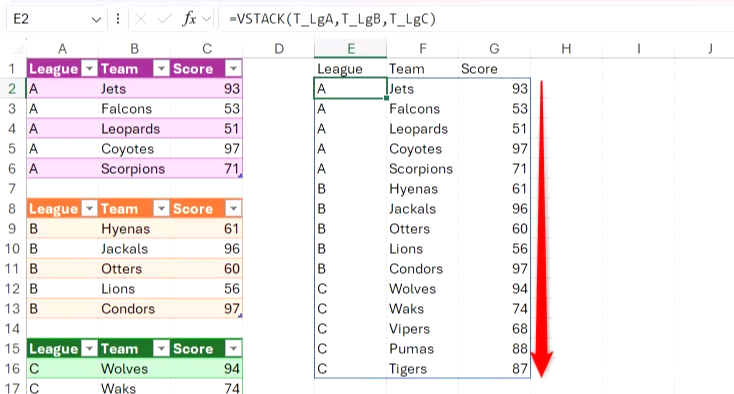
Excel에서는 필터 버튼을 사용하여 동적 배열의 순서를 변경할 수 없습니다. 수식을 입력한 셀만 활성 셀로 간주되기 때문입니다. 다른 모든 셀은 활성 셀에서 발생한 데이터만 포함하는 역할을 하므로, 기술적으로 정렬할 수 있는 값이 없습니다.

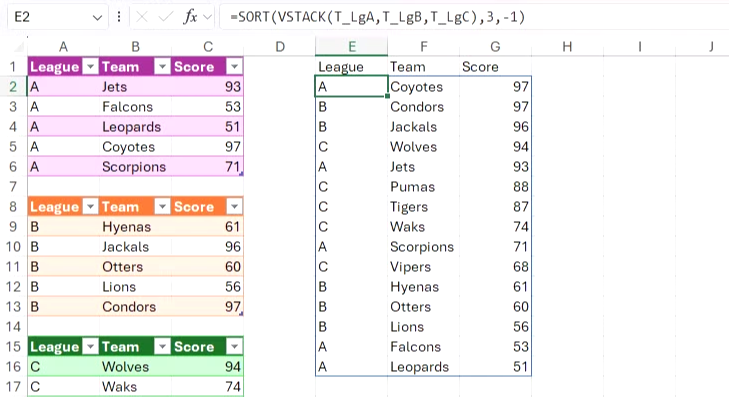
대신, SORT 함수 내부에 VSTACK 수식 전체를 중첩합니다.
=SORT(VSTACK(T_LgA, T_LgB, T_LgC), 3, -1)
여기서 3 (SORT 함수의 두 번째 인수)은 Excel에 배열을 세 번째 열로 정렬하라고 지시하고, -1(SORT 함수의 세 번째 인수)은 Excel에 이 열을 내림차순으로 정렬하라고 지시합니다.
HSTACK과 함께 SORT를 사용하는 경우 SORT 함수의 두 번째 인수는 결과를 정렬할 행을 나타내고, 세 번째 인수는 오름차순의 경우 1, 내림차순의 경우 -1 이며, 네 번째 인수는 Excel에서 수직이 아닌 수평으로 정렬한다는 것을 알 수 있도록 TRUE라야 합니다.
마치며
VSTACK과 HSTACK은 Excel에서 데이터를 재구성하는 유일한 함수는 아닙니다 . 예를 들어 TOCOL 및 TOROW 함수를 사용하면 배열을 단일 열이나 행으로 변환하고, WRAPCOLS 및 WRAPROWS 함수를 사용하면 1차원 열이나 행을 2차원 배열로 변환하며, PIVOTBY 함수를 사용하면 피벗 테이블 없이도 수치를 그룹화하고 집계할 수 있습니다. 참고하시기 바랍니다.
'Excel' 카테고리의 다른 글
| Excel의 REDUCE 함수는 훌륭하지만 이것보다 더 신뢰하는 오래된 함수 (0) | 2026.02.19 |
|---|---|
| Excel에서 DROP 함수를 사용하는 방법 (0) | 2026.02.18 |
| Excel 시트가 느려지는 3가지 수식 해결 방법 (1) | 2026.02.12 |
| 여러 개의 제목 행이 있는 Excel 데이터 쉽게 수정하는 방법 (0) | 2026.02.11 |
| Excel에서 스스로 업데이트되는 상위 10개 목록 만들기 (0) | 2026.02.10 |