들어가기 전에
웹 스크래핑은 프로그래밍이나 특수 도구를 사용하여 웹사이트에서 데이터 추출을 자동화하는 기술을 말하며, 시장 조사나 데이터 분석, 경쟁 정보 등의 작업을 위한 기초 자료로 사용됩니다. 시간을 절약하고 인터넷에서 귀중한 정보를 추출하는 강력한 도구입니다.

※ 이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: Web Scraping With 5 Different Methods: All You Need to Know
- URL: https://heartbeat.comet.ml/web-scraping-with-5-different-methods-all-you-need-to-know-403a59fceea0
개요
웹 스크래핑은 생각만큼 간단하지 않습니다. 그 과정에서 어려움에 직면할 수도 있습니다. HTML에 대한 어느 정도의 기본 지식이 필요합니다.
- 동적 웹사이트 구조: 최신 웹사이트는 동적 JavaScript 구조를 사용하며 정확한 데이터 추출을 위해 Selenium과 같은 도구가 필요합니다.
- 스크래핑 방지 : IP 블록과 CAPTCHA는 일반적인 억제 수단입니다. IP 주소 순환과 같은 전략은 이러한 장애물을 극복하는 데 도움이 될 수 있습니다.
- 법적 및 윤리적 고려 사항 : 법적 영향을 피하기 위해서는 웹사이트의 이용 약관을 따르는 것이 중요합니다. 윤리적 관행을 우선시하고 허가를 요청하십시오.
- 데이터 품질 및 일관성 : 웹사이트를 업데이트하는 동안 데이터 품질을 유지하는 것은 지속적인 과제입니다. 정확하고 안정적인 추출을 보장하려면 스크래핑 스크립트를 정기적으로 업데이트하세요.
방법 1: BeautifulSoup 및 Requestes
첫 번째 방법은 널리 사용되는 BeautifulSoup 및 Requests 라이브러리를 사용합니다. 이러한 도구를 사용하면 HTML을 쉽게 분석하고 웹 페이지 구조를 탐색할 수 있습니다. 다음은 샘플 Python 코드입니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Send a GET request to the specified URL
response = requests.get(url)
# Step 2: Parse the HTML content of the response using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Step 3: Save the HTML content to a text file for reference
with open("imdb.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb.txt")
# Step 4: Extract movie data from the parsed HTML and store it in a list
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.find('div', class_='ipl-rating-star').find('span', class_='ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.find('span', class_='ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Step 5: Create a Pandas DataFrame from the extracted movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
df
각 웹 스크래핑 방법에서는 대상 HTML 요소를 더 명확하게 볼 수 있도록 HTML을 imdb.txt 파일에 저장합니다. 최종 결과물은 다음과 같습니다.
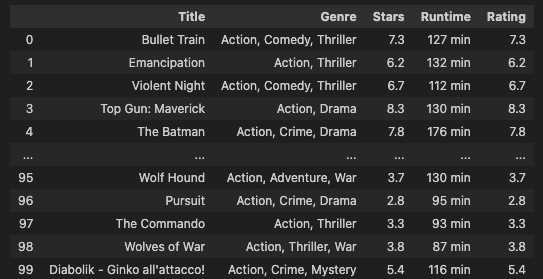
방법 2: 스크래피
스크래피(Scrapy)는 강력하고 유연한 웹 스크래핑 프레임워크입니다. 아래는 스크랩을 사용하는 방법을 보여주는 코드 스니펫입니다.
# Import necessary libraries
import scrapy
from scrapy.crawler import CrawlerProcess
# Define the Spider class for IMDb data extraction
class IMDbSpider(scrapy.Spider):
# Name of the spider
name = "imdb_spider"
# Starting URL(s) for the spider to crawl
start_urls = ["https://www.imdb.com/list/ls566941243/"]
# start_urls = [url]
# Parse method to extract data from the webpage
def parse(self, response):
# Iterate over each movie item on the webpage
for movie in response.css('div.lister-item-content'):
yield {
'title': movie.css('h3.lister-item-header a::text').get(),
'genre': movie.css('p.text-muted span.genre::text').get(),
'runtime': movie.css('p.text-muted span.runtime::text').get(),
'rating': movie.css('div.ipl-rating-star span.ipl-rating-star__rating::text').get(),
}
# Initialize a CrawlerProcess instance with settings
process = CrawlerProcess(settings={
'FEED_FORMAT': 'json',
'FEED_URI': 'output.json', # This will overwrite the file every time you run the spider
})
# Add the IMDbSpider to the crawling process
process.crawl(IMDbSpider)
# Start the crawling process
process.start()
import pandas as pd
# Read the output.json file into a DataFrame (jsonlines format)
df = pd.read_json('output.json')
# Display the DataFrame
df.head()
방법 3: 셀레늄
셀레늄(Selenium)은 동적 웹 스크래핑에 자주 사용됩니다. 기본적인 예는 다음과 같습니다.
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
# URL of the IMDb list
url = "https://www.imdb.com/list/ls566941243/"
# Set up Chrome options to run the browser in incognito mode
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
# Initialize the Chrome driver with the specified options
driver = webdriver.Chrome(options=chrome_options)
# Navigate to the IMDb list URL
driver.get(url)
# Wait for the page to load (adjust the wait time according to your webpage)
driver.implicitly_wait(10)
# Get the HTML content of the page after it has fully loaded
html_content = driver.page_source
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Save the HTML content to a text file for reference
with open("imdb_selenium.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb_selenium.txt")
# Extract movie data from the parsed HTML
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Create a Pandas DataFrame from the collected movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
print(df)
# Close the Chrome driver
driver.quit()
셀레늄의 핵심은 셀레늄 웹드라이버로 제어되는 크롬 브라우저의 동작을 사용자 지정하는 설정인 크롬 옵션에 있습니다. 이러한 옵션을 통해 시크릿 모드, 창 크기, 알림 등을 제어할 수 있습니다. 다음은 유용하게 사용할 수 있는 몇 가지 중요한 Chrome 옵션입니다.
# Runs the browser in incognito (private browsing) mode.
chrome_options.add_argument("--incognito")
# Runs the browser in headless mode, i.e., without a graphical user interface.
# Useful for running Selenium tests in the background without opening a visible browser window.
chrome_options.add_argument("--headless")
# Sets the initial window size of the browser.
chrome_options.add_argument("--window-size=1200x600")
# Disables browser notifications.
chrome_options.add_argument("--disable-notifications")
# Disables the infobar that appears at the top of the browser.
chrome_options.add_argument("--disable-infobars")
# Disables browser extensions.
chrome_options.add_argument("--disable-extensions")
# Disables the GPU hardware acceleration.
chrome_options.add_argument("--disable-gpu")
# Disables web security features, which can be useful for testing on localhost without CORS issues.
chrome_options.add_argument("--disable-web-security")
이러한 옵션은 요구 사항에 따라 결합하거나 개별적으로 사용할 수 있습니다. 웹드라이버.Chrome 인스턴스를 생성할 때 옵션 매개변수를 사용하여 이러한 옵션을 전달할 수 있습니다.
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
이러한 옵션은 웹 자동화 또는 테스트에 Selenium을 사용할 때 브라우저의 동작에 대한 유연성과 제어 기능을 제공합니다. 특정 사용 사례 및 요구 사항에 따라 옵션을 선택하세요.
방법 4: Requests and lxml
lxml은 C 라이브러리 libxml2 및 libxslt와 연결되는 Python 라이브러리로, 속도와 XML 기능을 간단한 기본 Python API와 결합하여 ElementTree와 유사하지만 추가적인 이점이 있습니다.
import requests
from lxml import html
import pandas as pd
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Send an HTTP request to the URL and get the response
response = requests.get(url)
# Parse the HTML content using lxml
tree = html.fromstring(response.content)
# Extract movie data from the parsed HTML
titles = tree.xpath('//h3[@class="lister-item-header"]/a/text()')
genres = [', '.join(genre.strip() for genre in genre_list.xpath(".//text()")) for genre_list in tree.xpath('//p[@class="text-muted text-small"]/span[@class="genre"]')]
ratings = tree.xpath('//div[@class="ipl-rating-star small"]/span[@class="ipl-rating-star__rating"]/text()')
runtimes = tree.xpath('//p[@class="text-muted text-small"]/span[@class="runtime"]/text()')
# Create a dictionary with extracted data
data = {
'Title': titles,
'Genre': genres,
'Rating': ratings,
'Runtime': runtimes
}
# Create a DataFrame from the dictionary
df = pd.DataFrame(data)
# Display the resulting DataFrame
df.head()
방법 5: LangChain 사용
이 글에 관심이 있는 분들은 오픈AI의 ChatGPT나 구글의 Gemini에 대해 알고 있으리라 생각합니다. LLM은 삶을 더 간단하게 만들어 주며, 다양한 작업에 사용하여 빠른 답변을 얻을 수 있습니다. 웹 스크래핑에도 사용할 수 있습니다.
import os
import dotenv
import time
# Load environment variables from a .env file
dotenv.load_dotenv()
# Retrieve OpenAI and Comet key from environment variables
MY_OPENAI_KEY = os.getenv("MY_OPENAI_KEY")
MY_COMET_KEY = os.getenv("MY_COMET_KEY")
필자의 LLM 프로젝트에서는 보통 Comet 프로젝트에 출력을 기록합니다. 이 데모에서는 01 URL만 사용하고 있습니다. 하지만 여러 URL을 반복해야 하는 경우 Comet LLM의 실험 추적 기능이 매우 유용합니다.
import comet_llm
# Initialize a Comet project
comet_llm.init(project="langchain-web-scraping",
api_key=MY_COMET_KEY,
)# Resolve async issues by applying nest_asyncio
import nest_asyncio
nest_asyncio.apply()
# Import required modules from langchain
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import create_extraction_chain
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Initialize ChatOpenAI instance with OpenAI API key
llm = ChatOpenAI(openai_api_key=MY_OPENAI_KEY)
# Load HTML content using AsyncChromiumLoader
loader = AsyncChromiumLoader([url])
docs = loader.load()
# Save the HTML content to a text file for reference
with open("imdb_langchain_html.txt", "w", encoding="utf-8") as file:
file.write(str(docs[0].page_content))
print("Page content has been saved to imdb_langchain_html.txt")
# Transform the loaded HTML using BeautifulSoupTransformer
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["h3", "p"]
)
# Split the transformed documents using RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
splits = splitter.split_documents(docs_transformed)
필요에 따라 HTML 레이아웃을 살펴보고 적합한 tags_to_extract를 선택해야 할 수도 있습니다. 이 데모에서는 영화 제목, 장르, 등급, 런타임을 추출하므로 <h3> 및 <p> 태그를 사용하겠습니다.
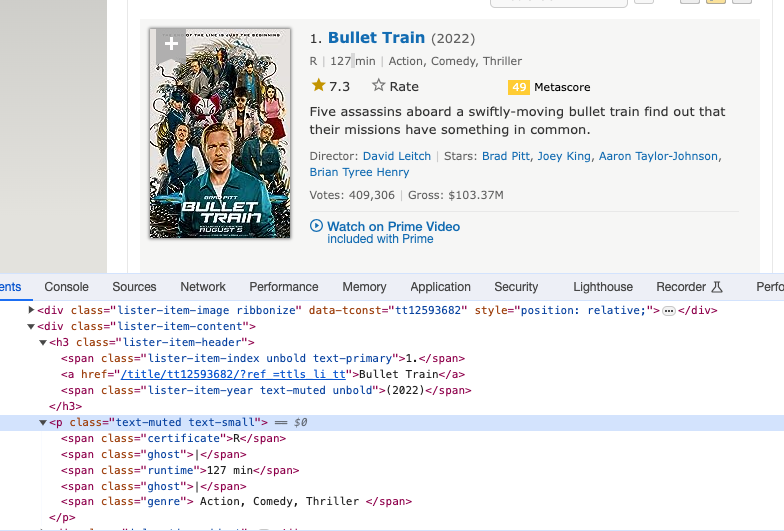
기본적으로 필요한 HTML을 얻은 후 LLM에게 "이 HTML을 사용하여 아래 스키마에 따라 정보를 입력해 주세요."라고 요청합니다.
# Define a JSON schema for movie data validation
schema = {
"properties": {
"movie_title": {"type": "string"},
"stars": {"type": "integer"},
"genre": {"type": "array", "items": {"type": "string"}},
"runtime": {"type": "string"},
"rating": {"type": "string"},
},
"required": ["movie_title", "stars", "genre", "runtime", "rating"],
}
def extract_movie_data(content: str, schema: dict):
"""
Extract movie data from content using a specified JSON schema.
Parameters:
- content (str): Text content containing movie data.
- schema (dict): JSON schema for validating the movie data.
Returns:
- dict: Extracted movie data.
"""
# Run the extraction chain with the provided schema and content
start_time = time.time()
extracted_content = create_extraction_chain(schema=schema, llm=llm).run(content)
end_time = time.time()
# Log metadata and output in the Comet project for tracking purposes
comet_llm.log_prompt(
prompt=str(content),
metadata= {
"schema": schema
},
output= extracted_content,
duration= end_time - start_time,
)
return extracted_content
최종 결과물은 아래와 같습니다.
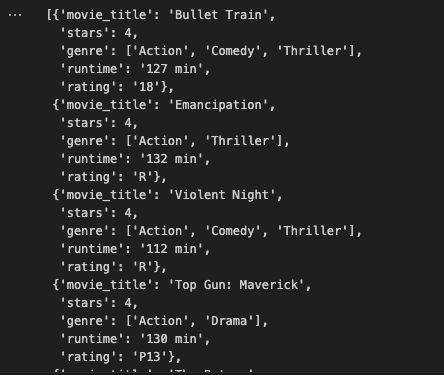
웹 스크래핑은 시도해 볼 가치가 있습니다. 웹사이트에서 정보를 수집하는 방법에는 여러 가지가 있습니다. LLM 기술을 구현하여 단순한 웹 스크래핑 이상의 것을 시도해 보시기 바랍니다.



'Python' 카테고리의 다른 글
| VS Code를 위한 10가지 유용한 테크닉 (7) | 2024.04.21 |
|---|---|
| 생산성과 워크플로를 개선할 12가지 VS Code 확장 (8) | 2024.04.20 |
| 파이썬으로 PDF 양식 데이터 추출 (7) | 2024.03.31 |
| 파이썬으로 QR 코드 생성하는 방법 (5) | 2024.03.30 |
| 파이썬 Matplotlib 마스터를 위한 단계별 가이드 (7) | 2024.03.23 |