들어가기 전에
피벗 테이블은 Excel에서 데이터를 요약하고 분석하는 대표적인 도구로 사용되어 왔으며, 다양한 작업에 효과적입니다. 하지만 그룹화를 조정하거나 데이터를 새로 고치기 위해 여러 메뉴를 클릭해야 하는 등 불편한 점도 있습니다. Excel의 GROUPBY 및 PIVOTBY 함수로 피벗 테이블 데이터를 집계하고 정리하는 새로운 방식을 소개합니다.

이 글은 아래 기사 내용을 토대로 작성되었습니다만, 필자의 개인 의견이나 추가 자료들이 다수 포함되어 있습니다.
- 원문: I wish I knew about these two Excel functions before struggling with pivot tables
- URL: https://www.makeuseof.com/two-excel-functions-before-struggling-with-pivot-tables/
GROUPBY: 간단한 데이터 집계를 위한 필수 함수
GROUPBY 함수는 이름 그대로의 기능을 수행합니다. 하나 이상의 열을 기준으로 데이터 행을 그룹화하고 각 그룹의 요약 값을 계산합니다. 저는 피벗 테이블을 설정하지 않고도 지역별 총 매출이나 제품별 평균 매출을 표시하는 데 이 함수를 사용합니다.
다양한 지역과 제품에 대한 거래를 추적하는 판매 데이터 세트가 있다고 가정해 보겠습니다. GROUPBY를 사용하면 피벗 테이블에서 전환하여 분석이 자동으로 업데이트되고 단일 수식으로 총계를 얻을 수 있습니다.
GROUPBY 함수의 사용 구문은 다음과 같습니다.
=GROUPBY(row_fields, values, function, [field_headers], [total_depth], [sort_order], [filter_array], [field_relationship])
GROUPBY 함수의 필수 매개변수는 다음과 같습니다.
- row_fields: 그룹화 기준으로 사용할 열. region과 같은 단일 열일 수도 있고, region과 product를 함께 사용하는 경우처럼 중첩된 그룹화가 필요한 경우 여러 열일 수도 있음.
- values: 집계하려는 데이터. 일반적으로 합계, 평균 또는 개수를 계산하려는 숫자 열
- function: 각 그룹에 대해 수행할 계산. 일반적인 옵션으로는 SUM, AVERAGE, COUNT, MAX, MIN 등이 있음. 배열을 처리하는 모든 함수를 사용할 수 있음.
다음은 선택적 매개변수입니다.
- field_headers: 출력에 열 머리글을 포함하려면 1로 설정하고, 제외하려면 0으로 설정. 이 값을 생략하면 Excel에서 기본적으로 머리글이 포함
- total_depth: 결과에 총합계 행 추가. 단일 총합계는 1로, 소계와 총합계는 2로 설정하는 식으로 설정
- sort_order: 그룹 정렬 방식 제어. 오름차순은 1, 내림차순은 -1을 사용하고, 데이터의 원래 순서를 유지하려면 생략
- filter_array: 그룹화하기 전에 포함할 행을 필터링하는 TRUE/FALSE 배열. 데이터의 하위 집합만 집계하려는 경우 유용
- field_relationship: Excel에서 그룹화 시 여러 행 필드 간의 관계를 해석하는 방식 제어. 각 값 조합을 고유한 그룹으로 처리하려면 0으로 설정하거나 생략. 두 번째 필드가 첫 번째 필드 아래에 중첩되는 계층적 관계를 만들려면 1로 설정
판매 스프레드시트에는 지역, 제품, 영업 담당자, 날짜, 금액 열이 있는 거래 기록이 있습니다. 지역별 총 매출을 계산하려면 다음 수식을 사용합니다.
=GROUPBY(A2:A50, E2:E50, SUM)
이렇게 하면 모든 행이 지역별로 그룹화되고(A열) 해당 금액 값(E열)이 합산됩니다. 결과적으로 각 지역과 총 매출을 보여주는 두 개의 열로 구성된 표가 생성되므로 피벗 테이블이 필요하지 않습니다.

지역별 및 제품별로 세분화된 매출을 보려면 row_fields 매개변수에 여러 열을 전달하면 됩니다.
=GROUPBY(A2:B50, E2:E50, SUM)
각 지역을 제품별로 세분화한 중첩된 그룹화를 생성하여 수익이 어디에서 발생하는지 더 자세히 볼 수 있습니다.
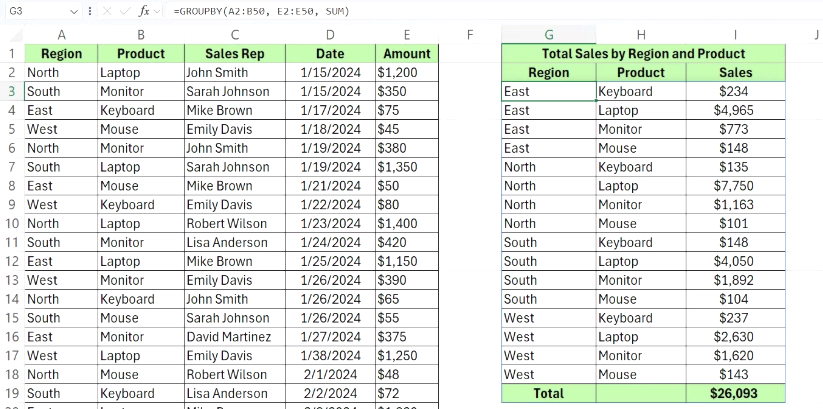
원본 데이터가 변경될 때마다 출력이 자동으로 업데이트됩니다. 수식은 항상 현재 데이터를 반영하므로 직접 새로 고치거나 다시 계산할 필요가 없습니다.
GROUPBY가 피벗 테이블보다 뛰어난 점 중 하나는 숫자뿐만 아니라 텍스트도 집계할 수 있다는 것입니다. 각 지역의 모든 영업 담당자를 쉼표로 구분된 목록으로 보고 싶다면 TEXTJOIN을 함수 매개변수로 사용할 수 있습니다.
예를 들어, 다음 수식은 지역별로 그룹화하고 각 그룹의 모든 영업 담당자 이름을 연결합니다.
=GROUPBY(A2:A50, C2:C50, LAMBDA(x, TEXTJOIN(", ", TRUE, x)))
피벗 테이블은 이런 작업을 할 수 없습니다. 개별 텍스트 값을 세거나 표시하는 데만 국한되며, 이를 하나의 출력으로 결합할 수 없습니다.
참고 영상:
PIVOTBY: 번거로움 없이 익숙한 피벗 레이아웃 만들기
PIVOTBY는 행과 열이 함께 작동하는 2차원 요약을 생성하여 데이터 집계를 한 단계 더 발전시킵니다. 차이점은 대화 상자를 클릭하는 대신 수식을 작성한다는 것입니다.
이 함수는 두 카테고리가 어떻게 교차하는지 확인해야 할 때 유용합니다. 예를 들어, 여러 제품의 지역별 매출을 보고 싶을 때, PIVOTBY는 모든 항목을 쉽게 확인할 수 있는 격자 형식으로 정렬해 줍니다.
여러 개의 선택적 매개변수가 포함된 긴 구문이 있습니다.
=PIVOTBY(row_fields, col_fields, values, function, [field_headers], [row_total_depth], [row_sort_order], [col_total_depth], [col_sort_order], [filter_array], [relative_to])
PIVOTBY 함수의 필수 매개변수는 다음과 같습니다.
- row_fields: 행을 정의하는 열. 출력 표의 왼쪽에 표시됨. 중첩된 행 그룹화에는 단일 열 또는 여러 열을 사용할 수 있음
- col_fields: 열을 정의하는 열. 이 값은 출력 표 상단에 표시되어 요약의 가로 방향 구성
- values: 집계하려는 데이터. 일반적으로 행과 열 값의 각 조합에 대해 합계, 평균 또는 개수를 계산하려는 숫자 열
- function: 행과 열 그룹의 각 교집합에 적용할 계산. 일반적으로 SUM, AVERAGE, COUNT, MAX, MIN 등이 사용
다음은 선택적인 매개변수입니다.
- field_headers: 출력에 헤더를 포함하려면 1로 설정하고, 제외하려면 0으로 설정. 이 값을 생략하면 Excel에서 기본적으로 헤더가 포함됨.
- row_total_depth: 행 합계와 소계를 추가할지 여부 제어. 총합계의 경우 1, 소계와 총합계의 경우 2 등으로 설정
- row_sort_order: 출력에서 행 그룹이 정렬되는 방식 결정. 오름차순은 1, 내림차순은 -1을 사용하고, 원본 데이터의 원래 순서를 유지하려면 생략
- col_total_depth: row_total_depth와 동일하지만 열 합계 나타냄. 출력 결과 오른쪽에 요약 열이 추가됨.
- col_sort_order: 출력 테이블의 열 그룹 정렬 제어. 오름차순은 1, 내림차순은 -1을 사용하고, 원래 순서를 유지하려면 생략
- filter_array: 피벗 계산에 소스 데이터의 어떤 행을 포함해야 하는지를 결정하는 TRUE/FALSE 배열
- relative_to: 특정 집계 함수를 사용할 때 합계와 백분율을 계산하는 방식 변경. 표준 합계를 계산하려면 0으로 설정하거나 생략. 행 합계에 대한 백분율로 값을 계산하려면 1로 설정하고, 열 합계에 대한 백분율로 값을 계산하려면 2로 설정
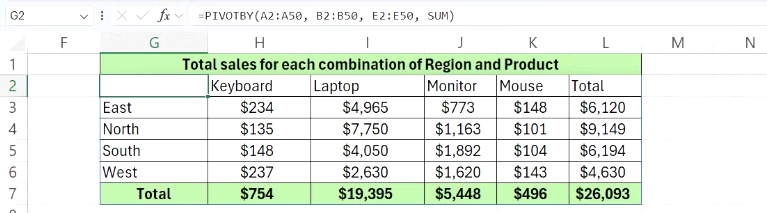
판매 데이터 스프레드시트를 사용하여 각 지역 및 제품 조합에 대한 총 판매액을 보고 싶다고 가정해 보겠습니다. 다음과 같이 작성합니다.
=PIVOTBY(A2:A50, B2:B50, E2:E50, SUM)
이 그룹은 지역별 행(A열)을 생성하고, 각 제품별 열(B열)을 생성하며, 각 교차점의 금액 값(E열)을 합산합니다. 출력 결과는 각 지역에서 각 제품의 정확한 판매량을 보여주는 표입니다. 또한, 수식은 데이터 변경에 따라 자동으로 업데이트됩니다.
마치며
GROUPBY와 PIVOTBY는 모두 수식이므로 스프레드시트의 나머지 부분과 잘 어울립니다. 다른 계산에서 해당 결과를 참조하거나, IF 문으로 묶거나, FILTER와 결합하여 조건부 요약을 만들 수 있습니다. 숨겨진 피벗 테이블 캐시나 디코딩해야 할 필드 설정이 없어 협업이 더욱 간편해지고 "이 수치는 어떻게 얻었나요?"라는 질문도 줄어듭니다. 자동으로 업데이트되는 대시보드를 구축할 수도 있습니다.
'Excel' 카테고리의 다른 글
| 파워 쿼리를 사용하여 지저분한 Excel 데이터를 정리하는 4가지 방법 (0) | 2026.04.08 |
|---|---|
| 수식 작성 방식을 바꿔 놓을 Excel 기호 하나 (0) | 2026.04.07 |
| Excel의 배열 상수에 대해 알아야 할 모든 것 (0) | 2026.04.02 |
| Excel에서 여전히 IF를 중첩 사용하고 있다면 이제 이렇게 하세요 (0) | 2026.03.31 |
| 모르고 있었지만 꼭 필요한, 최고의 시간 절약 MS Office 팁 6가지 (0) | 2026.03.27 |